Notes about writting a telnet filter in N-Code
Step 1: understand telnet and its attacks
Documentation sources for telnet: RFCs (about 38 of them are related to telnet,
but the most important are: 854, 855, 856, 857, 858, 1073, 1408, 1409, 1572).
To gather data concerning attacks: search securityfocus vulnerability archive
(found ~15 attacks), then Hacking Exposed, a Hacker's Guide...
Finally, found 17 attacks, that can be classified in 3 cathegories: username|password buffer overflows, other buffer overflows (used in general for DoS), telnet flaws (aspect of the protocol that allow attacks, like ENVIRON options), bad programming (telnetd with flaws like sensible commands that can be used by everyone). Each attack can be ranked: very easy to catch (**), easy to catch (*), could be catch but might not be a good idea (~), and can't be caught (-). Here is a short classification of telnet attacks.
Step 2: relax and think... (filter characteristics)
Most of the attacks found could be handled by searching for some signature
in the telnet packets. This kind of approach has known drawbacks: it is indeed
easier to implement, but hard to update, and unable to 'understand' the protocol,
thus inefficient in complex situations.
A better approach should be to write a filter that 'disassemble' the telnet
stream, dividing the data into the telnet option stream, and the user-server
data stream. Such a filter would also provide anomaly detection, by checking
for the validity of the telnet option stream and the user data stream.
The attacks listed above enable us to define a few properties that a good telnet filter should possess:
If we can write a filter matching these criteria, we would be able to detect known telnet attacks (username|password overflows, telnet option negociation, brute force). New attacks are usualy just variants of older ones (like a new pattern in buffer overflow, or a different telnet option misuse): they would either be caught by the existing rules (buffer overflow = too long, or with binary characters), or could easily be checked (a new telnet option keyword in a list). Furthermore, unknown attacks due to incorectly formated or unknown telnet blocks would be detected by the disassembling engine.
Conclusion: this would be a great filter :)
Step 3: problem solving (filter design)
Disassembling the telnet stream is easy. The telnet option stream is organized
as following: inserted inside the user data stream are telnet option blocks.
They always begin with a special escape byte (value: #FF), which can be followed
by 1 or 2 bytes of telnet option negociation, or by an arbitrary stream of byte
of telnet subnegociation option. This last kind of block always ends with the
sequence # FF F0. It is thus easy to extract telnet blocks from the telnet stream.
Moreover, the second byte of these blocks is set to define the type of option
the block is about. For blocks of 2 or 3 bytes length, this byte can take only
a few wellknown values. Checking for these values enables to detect unknown
non-official options. Not finding a FFF0 at the end of subnegociation block
is also an anomaly.
We can therefore write a telnet stream parser in 3 layers: a layer to separate
telnet blocks from the telnet data stream, a layer to check the validity of
telnet option blocks, and a layer to check the validity of telnet subnegociation
option blocks. Any anomaly should be caught. Subnegociation blocks should be
checked for known sensible telnet subnegociation options.
Now we have to analyse the user data part of the telnet stream. It will contain
2 kind of data: server to client data, and client to server data. We need to
identify, from the server, what are username and password prompts, and what
are answers to a user commands. From the user, we need to know what is a username,
a password, or a command to the shell. We should not forget either the possibility
let by the Authentication option (rfc 1409), that will shortcut the usual username/password
authentication process.
This is a hard part, because telnet has no standard prompt message to ask the
user for authentication. We look below at 2 possible solutions:
This last method was finally choosen for writting the filter, and works well even in tricky situations: the filter does recognize precisely when the user types a username, password or has began its session.
It is now easy to identify failed login attempts (a password prompt followed by a username prompt), and thus to catch brute force attacks.
Step 4: writing the filter
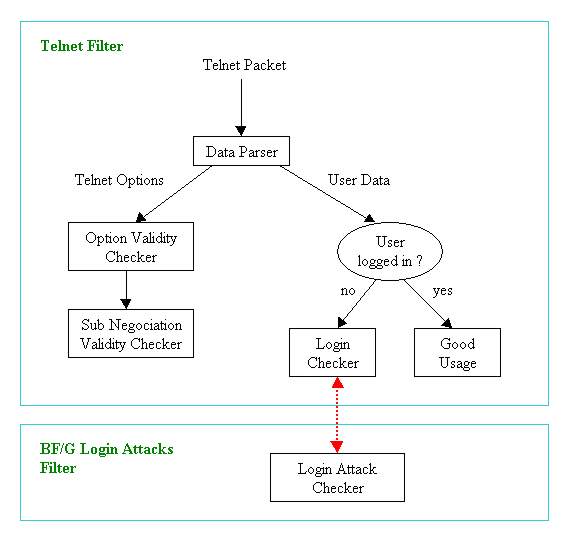
My implementation of the filter described above have the following structure:
And here are the source files !! telnet.nfr, telnet.values
Rem:
- to debug, it's usefull to give a number to all messages: global variable
incremented at each alert
- need for a conversion from byte to hex representation. Did it with a hash
with 256 entries (thank you Fredrick !)
- about N-Code: apparently, the best way to avoid n-code inner bugs is to use
a reduced structural and syntaxical set of n-code possibilities. For example:
avoid systematically nested function calls, always use intermediary variable,
always declare blocks with {} even if they contain only 1 line of code...
Step 5: testing the filter
The filter was tested in depth, and passed every test (brute force (Brutus), buffer overflow and binary buffers, telnet dissassembly, bad user monitor, identification of username|password|login in all situations...).
BUT !
ENVIRON variables handling was not tested, and all simulation were done with only 2 different telnetd (windows 2000 own telnetd, and fictional telnetd), and 2 telnet clients (unix & windows standard clients). Tests in 'real life' are strongly advised...